The present analysis, using the NLSY97, attempts to model the structural relationship between the latent second-order g factor extracted from the 12 ASVAB subtests, the parental SES latent factor from 3 indicators of parental SES, and the GPA latent factor from 5 domains of grade point averages. A structural equation modeling (SEM) bootstrapping approach combined with a Predictive Mean Matching (PMM) multiple imputation has been employed. The structural path from parental SES to GPA, independently of g, appears to be trivial in the black, hispanic, and white population. The analysis is repeated for the 3 ACT subtests, yielding an ACT-g latent factor. The same conclusion is observed. Most of the effect of SES on GPA appears to be mediated by g. Adding grade variable substantially increases the contribution of parental SES on the achievement factor, which was partially mediated by g. Missing data is handled with PMM multiple imputation. Univariate and multivariate normality tests are carried out in SPSS and AMOS, and through bootstrapping. Full result provided in EXCEL at the end of the article.
1. Introduction.
According to Jensen (1998, chap. 14) the IQ g factor “is causally related to many real-life conditions, both personal and social. All these relationships form a complex correlational network, or nexus, in which g is the major node” (p. 544). There could be some mediation through g between past economic status (e.g., familial SES) and future status. In a longitudinal study, for example, g would be the most (or one of) meaningful predictor of future outcome such as social mobility (Schmidt & Hunter, 2004), even controlling for SES, as evidenced from sibling studies of the sibling differences in IQ/g (Murray, 1998). On the other hand, non-g component of IQ tests do not have meaningful predictive validity (Jensen, 1998, pp. 284-285) in terms of difference in incremental R² (when non-g is added after g versus when g is added after non-g).
The fact that complexity (of occupation) will mediate the relationship between IQ and income (Ganzach et al., 2013) or job complexity mediating IQ-performance correlation (Gottfredson, 1997, p. 82) is in line with suggestion that cognitive complexity is the main ingredient in many g-correlates (Gottfredson, 1997, 2002, 2004; & Deary, 2004). The decline in standard deviation (SD) in IQ scores with increasing occupational level also supports this interpretation (Schmidt & Hunter, 2004, p. 163) as it would mean that success depends on a minimum cognitive threshold that tends to increase at higher levels of occupation.
Opponents of such interpretation usually argue that IQ tests measure nothing more than knowledge, mostly based on school and experiences, and that the question of complexity is irrelevant. This assumption can’t readily explain individual and group differences on tests that are proven to be impervious to learning and practice and, instead of being dependent on knowledge, merely reflect the capacity for mental transformation or manipulation of the item’s elements in tests that are relatively culture-free (e.g., Jensen, 1980, pp. 662-677, 686-706; 2006, pp. 167-168, 182-183). Because the more complex jobs depend less on job knowledge, they have less automatable demands which is analogous to fluid g rather than crystallized g (Gottfredson, 1997, pp. 84, 97; 2002, p. 341). Additionally, the declining correlation between experience and job performance over the years (Schmidt & Hunter, 2004, p. 168) suggests that lengthy experience (e.g., through accumulated knowledge) does not compensate for low IQ. Knowledge simply doesn’t appear as the active ingredient underlying the IQ-success association.
There have been suggestions that covariations between g and social status works through an active gene-environment correlation as individuals increasingly shape their life niches over time (Gottfredson, 2010). To illustrate this, Jensen (1980, p. 322) explains that success itself (e.g., due in part to higher g) acts as a motivational factor magnifying the advantage of having a higher IQ (g) level. Or the reverse when failures accumulate over time.
Gottfredson (1997, p. 121) and Herrnstein & Murray (1994, ch. 21-22) expected that, over time, the cognitive load of everyday life would tend to increase; Gottfredson believed that to be the inevitable outcome of societies’ modernization, and Herrnstein & Murray propose a complement, which is government’s laws make life more cognitively dependent because of the necessity to deal, cope with the new established laws. Theoretically, this sounds fairly reasonable. Given this, we should have expected IQ-correlates (notably with the main variables of economic success) to have increased over the past few decades. Strenze (2007) said there wasn’t any trend at all. Several explanations include range restriction in years (1960s-1990s in Strenze data) which is obvious because there wasn’t probably any drastic change in life within this “short” period of time. Another explanation could be that, over time, all other things are not equal, i.e., other alternative factors fluctuate in both directions and could have masked the relationship between cognitive load and time.
2. Method.
I will demonstrate presently that parents’ SES predicts children’s achievement (GPA+educational years) independently of g but also through g (ASVAB or ACT) by use of latent variable approach. Next, I use a latent GPA as independent var.
2.1 Data.
Of use presently is the NLSY97. Available here (need free account). The variables included in the CFA-SEM model are parental income (SQRT applied in order to respect distribution normality), mother and father education, and GPA english, foreign languages, math, social science, life science, and the 12 ASVAB subtests. All these variables have been age/gender adjusted, except parental grade/income. Refer to the syntax here.
To be clear with the ASVAB subtests :
GS. General Science. (Science/Technical) Knowledge of physical and biological sciences.
AR. Arithmetic Reasoning. (Math) Ability to solve arithmetic word problems.
WK. Word Knowledge. (Verbal) Ability to select the correct meaning of words presented in context and to identify best synonym for a given word.
PC. Paragraph Comprehension. (Verbal) Ability to obtain information from written passages.
NO. Numerical Operations. (Speed) Ability to perform arithmetic computations.
CS. Coding Speed. (Speed) Ability to use a key in assigning code numbers to words.
AI. Auto Information. (Science/Technical) Knowledge of automobile technology.
SI. Shop Information. (Science/Technical) Knowledge of tools and shop terminology and practices.
MK. Math Knowledge. (Math) Knowledge of high school mathematics principles.
MC. Mechanical Comprehension. (Science/Technical) Knowledge of mechanical and physical principles.
EI. Electronics Information. (Science/Technical) Knowledge of electricity and electronics.
AO. Assembling Objects. (Spatial) Ability to determine how an object will look when its parts are put together.
More information on ASVAB (here) and transcript (here).
2.2. Statistical analysis.
SPSS is used for EFA. AMOS software is used for CFA and SEM analyses. All those analyses have assumptions. They work best with normally distributed data (univariate and multivariate) and continuous variables. AMOS can still perform SEM with categorical variables using Bayesian approach. Read Byrne (2010, pp. 151-160) for an application of Bayesian Estimation.
Structural equation model is a kind of multiple regression which allows us to decompose the correlations into direct and indirect paths among construct (i.e., latent) variables. We can see it as a combination of CFA and path analysis. There is a huge difference between path analysis and SEM in the sense that a latent variable approach (e.g., SEM) has the advantage of removing measurement errors in estimating the regression paths. This results in higher correlations. There is no certainty for minimum N. The golden rule is N>200, but some examples include N of 100 or 150 that work well (convergence and proper solution).
CFA requires continuous and normally distributed data (When the data variables are of ordinal type (e.g., ‘completely agree’, ‘mostly agree’, ‘mostly disagree’, ‘completely disagree’), we must rely on polychoric correlations when two variables are categorical or polyserial correlations when one variable is categorical and the other is continuous. CFA normally assumes no cross-loadings, that is, subtests composing the latent factor “Verbal” are not allowed to have significant loadings on another latent factor, e.g., Math. Even so, forcing a (CFA) measurement model to have zero cross-loadings when EFA reveals just the opposite will lead to misspecification and distortion of factor correlations as well as factor loadings (Asparouhov & Muthén, 2008).
But when there are cross-loadings, it is said that there is a lack of unidimensionality or lack of construct validity, in which case, for instance, parceling (i.e., averaging) items is not recommended as indicators to be used in building a latent factor (Little et al., 2002). Having two (or more) latent factors is theoretically pointless if the observed variables load on every factors, in which case we should not have assumed the existence of different factors in the first place.
It is possible to build latent factors in SEM with only one observed variable. This is done by fixing the error term of that observed variable to a constant (e.g., 0.00, 0.10, 0.20, …). But even fixing the (un)reliability of that ‘latent factor’ does not means it should be treated or interpreted as a truly latent factor because in this case it is a “construct” by name only.
By definition, a latent variable must be an unobserved variable assumed to cause the observed (indicator) variables. In this sense, he is called a reflective construct, and this is why the indicators have arrows going into them with an error term. The opposite is a formative construct where the indicators are assumed to cause the construct (which becomes a weighted sum of these variables), and this is why the construct itself has an arrow going into him with an residual (error term, or residual variance). This residual represents the “represents the impact of all remaining causes other than those represented by the indicators included in the model” (Diamantopoulos et al., 2007, p. 16). Hence the absence of residual term is an indication that formative indicators are modeled as to account for 100% of the variance in the formative construct, a very unlikely assumption.
If we want to perform a formative model, a special procedure is needed to achieve identification (MacKenzie et al., 2005, p. 726; Diamantopoulos et al., 2007, pp. 20-24). For example, instead of having three verbal indicators caused by a latent verbal, we must draw the arrows from those (formative) indicators to the latent and then fix one of these paths to 1, and each formative construct having at least 2 (unrelated) observed variables and/or reflective latent variables that are caused by this formative construct. Finally, the formative indicators causing the construct should covary (double headed arrow) among them. Given the controversy and ongoing debate surrounding the formative models and by extension the MIMIC (multiple indicator multiple cause) models, I will just ignore this approach. The kind of latent variables used presently are of reflective kind.
2.2.1. Fundamentals.
a) Practice.
AMOS output usually lists 3 models : 1) default 2) saturated 3) independence model. The first illustrates the model we have specified (actually could be called reduced model, or over-identified), this is the one we are interested in. The second is a (full) model that assumes everything is related to everything (just-identified) with direct path from each variable to each other; it has a perfect fit but this in itself is meaningless. The third assumes that nothing is related to anything, or the null model (no parameters estimated).
In SEM, the model needs to be well specified. Otherwise the model is said to be misspecified (disparity between real-world relationships and model relationships), either because of over-specification (contrain irrelevant explanatory variables) or under-specification (absence of relevant explanatory variables). This can occur when the model specifies no relationship (equal to zero) between two variables when their correlation was in fact non-zero.
Some problems in modeling can even cause the statistical program to not calculate parameters estimates. There can be “under-identification” which causes troubles with the model. This appears when there are more unknown parameters than known parameters, resulting in negative degrees of freedom (df). At the Amos 20 User’s Guide, page 103 displays a structural path diagram with the explanation about how to make the model identified.
To better understand the problem of (non)identification, just use an example with 3 variables, X, Y, Z. This means we have 6 pieces of information : the variance for each variables X, Y, and Z, thus 3 variances, plus the covariance of each variables with one another, that is, X with Y, Y with Z, X with Z, thus 3 covariances. Identification problems emerge when the number of freely estimated parameters exceeds the pieces of information available in the actual sample variance-covariance matrix.
Concretely, such model 3 (knowns) – 4 (unknowns; to be estimated) = -1 df is clearly no good because calculation of the model parameters cannot proceed. Thus, more constraints need to be imposed in order to achieve identification. If, on the other hand, the df is equal to zero, the model is said to be “just-identified”, meaning there is a unique solution for the parameters while goodness of fit cannot be computed. In that case, the model fit with regard to the data is perfect. And if df is greater than zero (more knowns than unknows) the model is said to be “over-identified”, which means that there are multiple solutions for at least some of the parameters. The best solution is chosen through maximization of the maximum likelihood function. However, there is no need to worry so much about model identification. AMOS won’t run or calculate the estimates if df is negative. This is seen in the panel left to the “Graphics” space, where the default model would have an “XX” instead of an “OK”.
Remembering what df is, is relevant to the concept of model parsimony and complexity. The more degrees of freedom the model has, and the more parsimonious it is. The opposite is model complexity which can be thought as the greater number of free parameters (i.e., unknowns to be estimated) in a model. Lower df indicates more complex models. Complexity can be increased just by adding more (free) parameters, e.g., paths, covariances, and even cross-loadings. To be sure, freeing a parameter means we allow the unknown (free) parameter to be estimated from the data. Free parameters are the added paths, covariance, or variables (exogenous or endogenous) that do not have their mean and variance fixed at a given value. But doing so has serious consequences on model fit when fit indices penalize for higher model complexity (see below).
In SEM, it is necessary to achieve identification by, among possibilities, fixing one of the factor loadings of the indicator (observed) variables at 1. The (observed, not latent) variable receiving this fixed loading of 1 is usually called a marker variable. It allows the variables to be expressed in the same scale, and thus are seen as standardized variables (with mean of 0, variance of 1). It does not matter which variable is chosen as marker, it does not affect estimates or model fit. Alternatively, we can select the latent factor and fix its variance at 1, the problem however emerges when this latent variable has an arrow going into him because in that case AMOS will not allow the path to be defined unless we suppress the constrained variance of 1 as AMOS requires.
Among other identification problems are the so-called empirical under-dentification, occuring when data-related problems make the model under-identified even if the model is theoretically identified (Bentler & Chou, 1987, pp. 101-102). For example, latent factors need normally 3 indicators at minimum, and yet the model will not be identified if one factor loading approaches zero. And similarly for a two-factor model that needs the correlation/covariance between the factors to be nonzero.
In SEM, parameters are the regression coefficients for paths between variables but also variance/covariance of independent variables. In the structural diagrams, the dependent or criterion variable(s) is (are) those having (receiving) a single-headed arrow going into them and not starting from them. They are called endogenous variables, as opposed to exogenous (i.e., predictor) variables. The covariances (non-causal relationship) are illustrated as curved double-headed arrows and, importantly, they cannot be modeled among endogenous variables or between endogenous and exogenous variables. Covariances involve only exogenous variables. And these exogenous var. should not have error terms because they are assumed to be measured without error (even though this assumption may seem unrealistic). AMOS would assume no covariance between exogenous var., if there is no curved double-headed arrow linking them or if that arrow has a covariance value of zero (see AMOS user guide, p. 61). Either way, this is interpreted as a constraint (not estimated by the program). Likewise, AMOS assumes a null effect of one variable on another if no single-headed arrow linked these two.

Here, the large circles are latent variables, small circles are called errors (e1, e2, …) or residuals in the case of observed (manifest) variables and disturbances (D) in the case of latent variables, and rectangles the observed variables (what we have in our raw data set).
In the above picture, we see the following number related to the disturbance of the latent SES : ‘0.’ … where the number on the left of the comma designates the mean of the error term, which is fixed at zero by default. The number on the right of the comma designates the variance of the error term. The absence of any number indicates we want to freely estimate the error variance; otherwise we can fix it at 0 or 1, or any other number between 0 and 1. But if we want to constrain the error/variable variances to be equal, we can do so by assigning them a single label (instead of a number) identical for all of them (AMOS user guide, pp. 43-45).
Again, if we decide not to fix the mean, there should be no number associated to the error term or latent factor. To do this, click on the circle of interest, and specify the number (0 or 1) we want to be fixed, or the number to be removed if we decide not to fix it at a constant.

Above we see the two predictor variables (ASVAB and SES) sharing a curved double-headed arrow, that is, they covary. In this way, we get the independent impact of X1 on Y controlled for the influence of X2, and the impact of X2 on Y controlled for X1. When reporting the significance of the mediation, it is still possible to report the standardized coefficient with the p-value of the unstandardized coefficient.
b) Methodological problems.
In assessing good fit in SEM, we must always proceed in two steps. First, look at the model fit for measurement model (e.g., ASVAB models of g) and, second, look at the structural model connecting the latent variables. In doing so, when a bad fit is detected, we can locate where it originates : the measurement or the structural portion of the SEM model.
When it comes to model comparisons (target versus alternative), Tomarken & Waller (2003, p. 583) noticed that most researchers do not acknowledge explicitly the plausibility of the alternative model(s) they were testing. If we had two predictors (X) affecting one outcome (Y) variables, and that in the real world, the two predictors are very likely to be related (say, scholastic tests and years of schooling), a model that assumes the two predictors to be uncorrelated is not plausible in real life, and therefore the alternative model has no meaning. The best approach would be to compare two (theoretically) plausible models because a model by definition is supposed to represent a theory having real-life implications.
In SEM, the amount of mediation can be defined as the reduction of the effect of X on Y variable when M is added as mediation. Say, X->Y is labeled path C in the model without M, and X->Y is labeled path C’ in the model with M whereas X->M is labeled A and M->Y is labeled B. And by this, the amount of mediation is the difference between C and C’ (C-C’) and the mediation path AB is equal to C-C’. The same applies for moderator variables; say, variables A, B, AxB (the interaction) and Y in model 1, with variables A, B, AxB, M (the mediation) and Y in model 2, where the difference in the direct path AxB->Y between model 1 and 2 is indicative of the attenuation due to the mediator M. See Baron & Kenny (1986) for a discussion of more complex models.
The pattern of a mediation can be affected by what Hopwood (2007, p. 266) calls proximal mediation. If the variable X causes Y through mediation of M variable, X will be more strongly related to M than Y to M if the time elapsed between X and M is shorter (say, 2 days) than between Y and M (say, 2 months). Conversely, when we refer to distal mediation if M is closer (in time) to Y, resulting in overestimation of M->Y and underestimation of X->M.
Hopwood (2007, p. 264) also explains how moderators (interaction effects) and curvilinear functions (effect varying at certain levels of M) can be included in a model. For X and M causing Y, we add an additional variable labeled XM (obtained by simply multiplying X by M, could be done in SPSS, for instance) causing Y. Furthermore, we add two additional variables, squared M and squared XM. The regression model is simply illustrated as follows : X+M+XM+M²+XM²=Y. Here, the XM² represents the curvilinear moderation. Gaskin has a series of videos describing the procedure in AMOS (Part_7, Part_8, Part_9, Part_10). See also Kline (2011, pp. 333-335). Although one traditional way of testing moderation is by comparing the effect of X on Y separately in the different groups (gender, race, …), if there was a difference in the relationship across the groups, an interaction effect may be thought to be operating. Nonetheless, this method is problematic because variance in X may be unequal across levels of M. In this case, differing effects of X on Y across levels of M are attributed to difference in range restriction among the groups, not moderation effect. Also, if measurement error of X is seen to differ across levels of M, this would be evidence of moderation effect (X->Y varying across levels of M). Latent variable approach (e.g., SEM) hopefully tends to attenuate this concerns. Note that an unstandardized regression coefficient, unlike correlation, is not affected by the variance of independent var. or measurement error in dependent var., and Baron & Kenny (1986, p. 1175) recommend their use in this case.
The construction of moderator variables in SEM has the advantage that it attenuates the measurement errors usually associated with the interaction term (Tomarken & Waller, 2005, pp. 45-46) although their use can have some complications (e.g., specifications and convergence problems). The typical way is to multiply all of the indicators (a1, a2, …) of the latent X by the indicators (b1, b2, …) of the latent M, such as a1*b1, a1*b2, a2*b1, a2*b2 and then by creating the latent variable using all of these interaction variables (see here). The same procedure is needed when modeling quadratic effect, e.g., creating a latent variable X² with a1^2, a2^2, and so on. Alternatively, Hopwood (2007, p. 268) proposes to conduct factor analysis with Varimax, to save the standardized factor score, and to create the interaction variable by multiplying these factor score variables.
In some scenarios, measurement errors can be problematic (Cole & Maxwell, 2003, pp. 567-568). When X is measured with error but not M and Y, the path X->M will be downwardly biased while M->Y and X->Y will be unaffected. For example, with X’s reliability of 0.8, a path of 0.8 assuming perfect reliability will then become 0.8*(SQRT(0.8))=0.72. When Y only is measured with error, only the path M->Y is biased. But when M is measured with error, the (direct) path X->Y is upwardly biased while the other two (indirect) paths are underestimated. Again, the latent variable approach is an appropriate solution for dealing with this problem. And this is one of the great advantage of SEM over simple path analysis.
In a longitudinal design, method shared variance can upwardly bias the correlations between factors when factors are measured by indicators assessed by the same method (or measure) rather than by different methods (e.g., child self-report vs. parent self-report). In the field of intelligence, method must be equivalent to the IQ tests measuring a particular construct (verbal, spatial, …) when the same measure is administered several times at different points in time. But repeated measures (or tests) over time is virtually impossible to avoid in longitudinal data (e.g., CNLSY79), so that such effect must be controlled by allowing correlated errors of same-method indicators across factors. In all likelihood, the correlation (or path) between factors would be diminished because the (upward biased) influence of method artifacts on the correlation have been removed. See Cole & Maxwell (2003, pp. 568-569). Several data analysts (Little et al., 2007; Kenny, 2013) added that we should test for measurement invariance of factor loadings, intercepts, and error variances, if we want to claim that the latent variable remains the “same” variable at each assessment time. Weak invariance (factors) is sufficient for examining covariance relations but strong invariance (intercepts) is needed to examine mean structures.
The same authors also address the crucial question of longitudinal mediation. Most of the studies use cross-sectional mediation, all the data having been gathered at the same time point. There is no time elapsing between the predictor, mediator and outcome (dependent) variables. Causal inferences are not possible. The choice of variables is important too. Retrospective measures are not recommended, for example. Other measures such as background can hardly be viewed as causal effects because these variables (e.g., education level) don’t move over time. But some others (e.g., income and job level) can move up and down over years.
In some cases, researchers proceed with an half-longitudinal approach, e.g., predictor (X) and mediator (M) measured at time #1, and outcome (Y) at time #2. They argue such approach is not appropriate either, that X->M will be biased because X and M coincide in time and that prior level of M is not controlled. Likewise, when M and Y have been assessed at the same time, but not X, then M->Y will be biased. Ideally, causal models must control for previous levels of M when predicting M and control for previous levels of Y when predicting Y. Using half-longitudinal design with 2 waves, we can still use X1 to predict M2 controlling for M1 and use M1 to predict Y2 controlling for Y1. See Little et al. (2007, Figure 3) for a graphical illustration. Although such practice is less bias-prone, we can only test whether M is partial mediator but not if M could be a full mediator. Furthermore, we cannot test for violation of the stationarity assumption. Stationarity denotes an unchanging causal structure, that is, the degree to which one set of variables produces change in another set remains the same over time. For example, if longitudinal measurement invariance (e.g., by constraining a given parameter to equal its counterparts at the subsequent waves) is violated, the stationarity assumption would be rejected.
Of course, the point raised by Cole & Maxwell (2003) is not incorrect but what they want is no less : predictor(s) at time1, mediator(s) at time2, outcome at time3. In other words, 3 assessment occasions. Needless to say, this goal is, in practice, virtually impossible to achieve by an independent, small team, with limited resources.
2.2.2. CFA-SEM model fit indices.
A key concept of SEM is to evaluate the plausibility of hypotheses modeled through SEM. Concretely, it allows model comparison by way of model fit indices. The best fitted model is selected based on these fit indices. A good fit is indicative that the model reproduces the observed covariance accurately but not necessarily that exogenous and mediators explain a great portion of the variance in the endogenous variables; even an incorrect model can be made to explain the data just by adding parameters to the point where df falls to zero. Associations and effects can be small with good model fit, if residual variances (% unexplained; specificity+error) are sufficiently high as to generate equality in the implied and observed variances (Tomarken & Waller, 2003, p. 586).
Browne et al. (2002) argue that very small residuals in observed variables, while suggesting good fit, could easily result in poor model fit as indicated by fit indices, in factor analysis and SEM. But the explanation is that fit indices are more sensitive to misfit (misspecifications) when unique variances are small than when they are large. Hence, “one should carefully inspect the correlation residuals in E (i.e., the residual matrix, E=S-Σ where s is sample data covariance and Σ fitted or implied covariance). If many or some of these are large, then the model may be inadequate, and the large residuals in E, or correspondingly in E*, can serve to account for the high values of misfit indices and help to identify sources of misfit.” (p. 418). The picture is thus complicated to the extent that all this means we should not rely exclusively on fit indices (with the exception of RMR/SRMR computed using these same residual correlation matrices) because they can be very inaccurate sometimes. Hopefully, the situation where error and specificity are so small as to reflect observed variables as being very high accurate measures of latent variables is likely to be rare.
Unfortunately, the reverse phenomenon is true. In a test of CFA models, Heene et al. (2011) discovered that decreasing factor loadings (which consequently increases unique variances) under any of these two kinds of misspecified models, 1) simple, incorrectly assuming no factor correlation, 2) complex, incorrectly assuming no factor correlation and no cross-loading, will cause increasing good model fitting, as a result of altering the statistical power to detect model misfit. In this way, a model would be validated by fit indices (e.g., χ²) erroneously. Even the popular RMSEA, SRMR and CFI are altered by this very phenomenon. Another gloomy discovery is the lack of sensitivity to misspecification (i.e., capability of rejecting models) for RMSEA when the number of indicators per factor (i.e., free parameters) increases, irrespective of factor loadings. Regarding properly specified models, it seemed that χ² and RMSEA are not affected by loadings size while SRMR and CFI could be.
Similarly, Tomarken & Waller (2003, p. 592, Fig.8) noted that, in typical SEM models, the power to detect misspecification, holding sample size constant, depend on 1) the magnitude of factor loadings and 2) the number of indicators per latent factors. Put it otherwise, the power to detect any difference in fit between models improves when 1) or 2) increases, but this improvement depends on sample size (their range of N was between 100 and 1000).
There are three classes of goodness-of-fit indices : absolute fit (χ², RMR, SRMR, RMSEA, GFI, AGFI, ECVI, NCP) which considers the model in isolation, incremental fit (CFI, NFI, (TLI) NNFI, RFI, IFI) which compares the actual model to the independent model where nothing is correlated to anything, and parsimonious fit (PGFI, PNFI, AIC, CAIC, BCC, BIC) adjusts for model parsimony (or df). An ideal fit index is one that is sensitive to misspecification but not to sample size (and other artifacts). What must be avoided is not necessarily trivial misspecification but the severe misspecification. Here’s a description of the statistics commonly used :
The χ²/df (CMIN/DF in AMOS), also called relative chi-square, is like a badness of fit, with higher values denoting bad fit because it evaluates the difference between observed and expected covariance matrices. However, χ² is too sensitive. The χ² increases with sample size (e.g., like NFI) and its value diminishes with model complexity due to reduction in degrees of freedom, even if the χ² divided by degrees of freedom overcomes some of its shortcomings. This index evaluates the discrepancy between the actual (and independence) model and the saturated model. The lower, the better. AMOS also displays p-values, but we never see a value like 0.000. Instead we have *** which means it’s highly significant. The p-value here is the probability of getting as large a discrepancy as occurred with the present sample and, so, is aimed to test the hypothesis that the model fits perfectly in the population.
In AMOS, PRATIO is the ratio of how many paths you dropped to how many you could have dropped (all of them). In other words, the df of your model divided by df of the independence model. The Parsimony Normed Fit Index (PNFI), is the product of NFI and PRATIO, and PCFI is the product of the CFI and PRATIO. The PNFI and PCFI are intended to reward those whose models are parsimonious (contain few paths) that is, adjusting for df. What is called the model parsimony is one that is less complex (less parameterized), making less restricted assumptions (think about Occam’s Razor).
The AIC/CAIC, BCC/BIC are somewhat similar to the χ² in the sense that it evalutes the difference between observed and expected covariances, low values are therefore indicative of better fit. Like the χ²/df, they adjust for model complexity. Absolute values for these indices are not relevant. What really is important is the relative index in comparing between models. Despite AIC being commonly reported, it has been criticized due to its tendency to favor more complex models as sample size (N) increases because the rate of increase in the badness of fit term increases with N even though its penalty term remains the same (Preacher et al., 2013, p. 39). AIC also requires sample size of 200 (minimum) to make its use reliable (Hooper et al., 2008). Unlike AIC, CAIC adjusts for sample size. For small or moderate samples, BIC/BCC often chooses models that are too simple, because of its heavy penalty (more than AIC) on complexity. Sometimes, it is said that BCC should be preferred over AIC.
The Adjusted (or not) Goodness of Fit Index (GFI, AGFI) should not be lower than 0.90. The higher, the better. The difference between GFI and AGFI is that AGFI adjusts for the downward biasing effect resulting from model complexity. These indices evaluate the relative amount of variances/covariances in the data that is predicted by the actual model covariance matrix. GFI is downwardly biased with larger df/N ratio, and could also be upwardly biased with larger number of parameters and sample size (Hooper et al., 2008). GFI is not sensitive to misspecification. Sharma et al. (2005) concluded that GFI should be eliminated. Note also that AGFI remains sensitive to N.
The PGFI and PNFI, respectively Parsimony Goodness-of-Fit Index and Parsimony Normed Fit Index, are used for choosing between models. We thus look especially at the relative values. Larger values indicate better fit. PGFI is based upon GFI and PNFI on NFI but they both adjust for df (Hooper et al., 2008). Both NFI and GFI are not recommended of use (Kenny, 2013). There is no particular recommended threshold (cut-off) values for them.
The comparative fit index (CFI) should not be lower than 0.90, this value is an incremental fit index which shows the improvement of a given model compared to the baseline (or null) model in which all variables are allowed to be uncorrelated. It declines slightly in more complex models and it is one of the measures least affected by sample size. By way of comparison, the TLI (sometimes called NNFI, non-normed fit index) is similar but it displays a lower index than CFI. Kenny (2013) recommends TLI over CFI, the former giving more penalty for model complexity (CFI adds a penalty of 1 for every parameter estimated). MacCallum et al. (1992, p. 496) and Sharma et al. (2005) found however that NNFI (TLI) is quite sensitive to sample size but this is a function of the number of indicators. Hooper et al. (2008) conclude the same, NNFI being higher in larger samples, just like the NFI. Also, due to its nature of being a non-normed value, it can go above 1.0 and consequently generates outliers when N is small (i.e., ~100) or when factor loadings are small (i.e., ~0.30).
RMSEA estimates the discrepancy related to the approximation, or the amount of unexplained variance (residual), or the lack of fit compared to the saturated model. Unlike many other indices, RMSEA provides its own confidence intervals (narrower lower/upper limits reflecting high precision) that measure the sampling error associated with RMSEA. The RMSEA should not be higher than 0.05, but some authors recommend the 0.06, 0.07, 0.08 and even 0.10 threshold cut-off. The lower, the better. In principle, this index directly corrects for model complexity, as a result, for two models that explain the data equally well, the simpler model has better RMSEA fit. RMSEA is affected by low df and sample size (greater values for smaller N) but not substantially, and can possibly become insensitive to sample size when N>200 (Sharma et al., 2005, pp. 938-939). These authors also indicate that the index is not greatly affected by the number of observed variables in the model, but Fan & Sivo (2007, pp. 519-520) and Heene et al. (2011, p. 327) reported that RMSEA declines considerably with higher number of observed variables (i.e., larger model size), which is the exact opposite of CFI and TLI that would indicate worse fit (although not always) as the number of indicators increases. In fact, it seems that most fit indices are affected by model types (e.g., CFA models vs. model with both exogenous and endogenous latent variables) to some extent. For this reason, Fan & Sivo (2007) argue that it is difficult to establish a flawless cut-off criteria for good model fit. Same conclusion has been reached by Savalei (2012) who discovered that RMSEA becomes less sensitive to misfit when the number of latent factors increases, holding constant the number of indicators or indicators per factor.
The RMR (Root Mean Square Residual) and SRMR (standardized RMR) again express the discrepancy between the residuals of the sample covariance matrix and the hypothesized covariance model. They should not be higher than 0.10. That index is an average residual value calculated using the residualized covariance matrix (equal to the fitted variance-covariance matrix minus sample variance-covariance matrix, and displayed in AMOS through “Residual moments” option) where the absolute standardized values >2.58 are considered to be large (Byrne, 2010, pp. 77, 86). It is interpreted as meaning that the model explains the correlations to within an average error of, say, 0.05, if the SRMR is 0.05. Because RMR and SRMR are based on squared residuals, they give no information about the direction of the discrepancy. RMR is difficult to interpret because it is dependent on the scale of observed variables, but SRMR corrects for this defect. The fit index for SRMR is lower with more parameters (or if the df decreases) and with larger sample sizes (Hooper et al., 2008). In AMOS, the SRMR is not displayed in the usual output text with the other fit indices but in the plugins “Standardized RMR”. An empty window is opened. Leave this box opened and click on “Calculate estimates”. The box will display the value of SRMR. But only when data is not missing. So we must use imputations.
The ECVI (Expected Cross Validation Index) is similar to AIC. It measures the difference between the fitted covariance matrix in the analyzed sample and the expected covariance matrix in another sample of same size (Byrne, 2010, p. 82). Smaller values denote better fit. ECVI is used for comparing models, hence the absence of threshold cut-off values for an acceptable model. Like AIC, the ECVI tends to favor complex models as N increases (Preacher, 2006, p. 235) because more information accrues with larger samples and models with higher complexity can be selected with greater confidence, whereas at small sample sizes these criteria are more conservative.
That being said, all statisticians and researchers would certainly affirm that it is necessary to report the χ² and df and associated p-values, even if we don’t trust χ². In my opinion, I would say it is better to report all indices we can. Different indices reflect different aspect of the model (Kline, 2011, p. 225). We must rely on fit indices but also on the interpretability of parameter estimates and theoretical plausibility of the model.
The rule of thumb values is arbitrary, varying with authors, and for this reason it is not necessary to follow these rules in a very strict manner. Cheung & Rensvold (2001, p. 249) rightly point out that fit indices are affected by sample size, number of factors, indicators per factor, magnitude of factor loadings, model parsimony or complexity, leading these authors to conclude that “the commonly used cutoff values do not work equally well for measurement models with different characteristics and samples with different sample sizes”. Fan & Sivo (2007) even add : “Any success in finding the cut-off criteria of fit indices, however, hinges on the validity of the assumption that the resultant cut-off criteria are generalizable to different types of models. For this assumption to be valid, a fit index should be sensitive to model misspecification, but not to types of models.” (p. 527). But if we are concerned with these threshold values, it seems that CFI is the more robust index. To the best of my knowledge, it is the less criticized one.
Finally, keep in mind that fit indices can be effected by missing data rates when a model is misspecified (Davey & Savla, 2010) although that differs with the nature of the misspecification.
The AMOS user’s guide (Appendix C, pp. 597-617) gives the formulas for the fit indices displayed in the output, with their description.
2.2.3. Dealing with missing values.
Traditional methods such as pairwise and listwise deletion are now considered as non-optimal ways to deal with missing data in some situations but in some other cases, listwise yields unbiased estimates in regression analyses when the missing values in any of the independent var. do not depend on the values of the dependent var. (Allison, 2002, pp. 10-12). “Suppose the goal is to estimate mean income for some population. In the sample, 85% of women report their income but only 60% of men (a violation of MCAR, missing completely at random), but within each gender missingness on income does not depend on income (MAR, missing at random). Assuming that men, on average, make more than women, listwise deletion would produce a downwardly biased estimate of mean income for the whole population.” (Allison, 2009, p. 75). MCAR seems to be a strong assumption and is a condition rarely met in most situations.
Generally, maximum-likelihood (ML) and multiple imputation (MI) are among the most popular and recommended methods. In the MI process, multiple versions of a given dataset are produced, each containing its own set of imputed values. When performing statistical analyses, in SPSS at least, the estimates for all of these imputed datasets are pooled (but some are not, e.g., standard deviations). This produces more accurate estimates than it would be with only one (single) imputation. The advantage of MI over ML is its general use, rendering it useable for all kind of models and data. The little disadvantage of MI over ML is that MI produces different results each time we use it. Another difference is that standard errors must be (slightly) larger in MI than in ML because MI involves a random component between each imputed data sets. The MAR assumption, according to Heymans et al. (2007, p. 8) and many other data analysts, cannot be tested, but these authors cited several studies revealing that models incompatible with MAR are not seriously affected (e.g., estimates and standard errors) when multiple imputation (MI) is applied. MI appears to minimize biases. In general, MI is more robust to assumptions’ violation than ML.
A distinction worth bearing in mind is the univariate imputation (single imputation variable) and the multivariate imputation (multiple imputation variables). The univariate version fills missing values for each variable independently. The multivariate version fills missing values while preserving the relationship between variables, and we are mostly concerned with this method because in most cases, data has missing values on multiple variables. We are told that “Univariate imputation is used to impute a single variable. It can be used repeatedly to impute multiple variables only when the variables are independent and will be used in separate analyses. … The situations in which only one variable needs to be imputed or in which multiple incomplete variables can be imputed independently are rare in real-data applications.” See here.
A point worth recalling is that the use of the imputed values in the dependent variable has been generally not recommended for multiple regressions. This does not mean that the dependent var. should not be included in the imputation procedure. Indeed, if dependent var. is omitted, the imputation model would assume zero correlation between the dependent and the independent variables. Dependent var. should probably be included in the final analysis as well.
On the best practices of multiple imputation, a recommendation is the inclusion of auxiliary variables, which do not appear in the model to be estimated but can serve the purpose of making MAR assumption more plausible (Hardt et al., 2012). They are used only in the imputation process, by including them along with the other incomplete variables. Because imputation is the process of guessing the missing values based on available values, it makes sense that the addition of more information would help making the “data guessing” more accurate. These variables must not be too numerous and their correlations with the other variables must be reasonably high (data analysts tend to suggest correlations around 0.40) in order to be useful for predicting missing values. The higher the correlations, the better. Some recommended that the ratio of subjects/variables (in the imputation) should never fall below 10/1. Alternatively, Hardt et al. (2012) recommend a maximum ratio of 1:3 for variables (with or without auxiliaries) against complete cases, that is, for 60 people having complete data, up to 20 variables could be used. Auxiliary is more effective when it does not have (or fewer) missing values. This is another advantage of MI over ML.
The best auxiliary variables are identical variables measured at different points in time. Probably the best way to use auxiliaries is to find variables that measure roughly the same thing as the variables involved in the final structural models.
Early MI theorists once believed that a set of 5 imputations is well enough to provide us with a stable final estimate. But after more research, others argue now that 20-100 imputations would be even better (Hardt et al., 2012). Allison (Nov 9, 2012) affirms that it depends on the % of missing values. For instance, with 10% to 30% missing, 20 imputations would be recommended, and 40 imputations for 50% missing. More precisely, the number of imputation should be more or less similar to the % of missing values; say, for 27% missing, 30 imputations would be reasonable. I don’t have the energy to run the analysis 20 or 40 times for each racial group, so I will limit my imputations to 5 data sets. Thus, in total, the SEM mediation analysis is conducted 18 times (original data + 5 imputed data, for the 3 racial groups) for the ASVAB.
A caveat is that some variables are restricted to a particular group of subjects. For example, a variable “age of pregnancy” should be available only for women and must have missing values for all men, a variable “number of cigarettes per day” available only to people having responded “yes” to the question “do you actually smoke”. The use of imputation could fill the data for men and non-smokers, which makes no sense. A solution is the so-called “conditional imputation” that allows us to impute variables which are defined within a particular subset of the data, and outside this subset, the variables are constant. See here.
And still another problem arises when we use categorical variables in the imputation model. Say, the variables can only take on 5 values, 1, 2, 3, 4, 5, like a Likert-type scale (e.g., personality questionnaire). This variable cannot “legally” have a value of, say, 1.6, or 3.3, or 4.8. It may be that linear regression method for imputation will not be efficient in that case. To this matter, Allison (2002, p. 56) recommends to round the imputed values. Say, we impute a binary variable coded 0 and 1, and the imputed values above 0.5 can be rounded to 1, below 0.5 rounded to 0. Sometimes, the values can be outside this range (below 0, above 1) but rounding is still possible. With continuous variables, there is no such problems. Even so, a categorical variable having many values, say education or grade level with 20 values, going from 1 to 20, can be (and is usually) treated as a continuous variable. On the other hand, hot deck and PMM imputations can easily deal with categorical variables. If, instead of PMM, we use the SPSS default method “Linear Regression” we will end up with illegal values everywhere. PMM gives the actual values that are in your data set. If your binary variable has only 0 and 1, PMM gives either 0 or 1.
It is also recommended to transform non-normal variables before imputation. Lee & Carlin (2009) mentioned that symmetric distribution in the data avoids potential biases in the imputation process.
An important question that has not been generally treated is the possible between-group difference regarding the correlations of the variables of interest. Some variables can be strongly related in a given racial/sex/cohort group but less so in another group. Because the aim of the present article is to compare the SEM mediation across racial group, and given the possibility of racial differences in the correlations, it is probably safer to impute the data for each racial group separately. This is easily done through FILTER function where we specify the value of the race variable to be entered. This method can ensure us that the correlations won’t be distorted by any race or group-interaction effects, even if the obvious drawbacks emerge when we work with small data. Another possibility is to create an interaction variable between the two variables in question and to include it in the imputation model (Graham, 2009, p. 562). But this would be of no interest if the interaction between the 2 relevant variables is not meaningful.
When we compute estimates from the different imputed data, we can (should) average them. However, we should not average t-, z-, F-statistics, or the Chi-Square (Allison, 2009, p. 84). For averaging standard errors, say, we have to apply Rubin (1987) formula because a simple “averaging method” fails to take into account the variability in imputed estimations, and those statistics (standard errors, p-values, confidence intervals, …) tend to be somewhat downwardly biased. For this analysis, I have applied Rubin’s formula for pooling SE, CI and the C.R. See attachment at the end of the post.
a) Multiple imputation on SPSS.
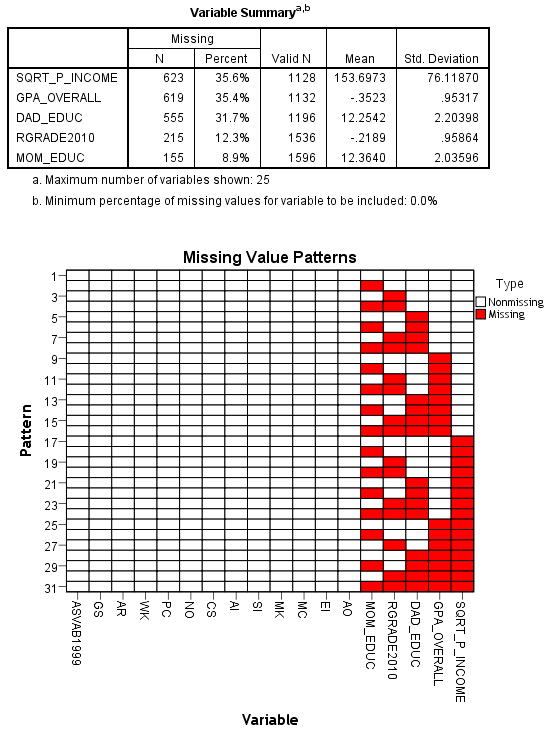
We go to “Multiple Imputation” option and then go to “Analyze Patterns” and include the variables we wish to use in SEM analysis. We get a chart that reveals the patterns of missing values in the selected variables. My window looks like this.
Initially, the minimum % of missing values is 10, but I choose to lower this value at 0.01. All of the variables supposed to be included in the CFA-SEM models should be selected. Grouping variables like “race” and “gender” are not needed here.
The chart we are interested in is the “Missing Value Patterns”. As we can see, there are clumps or islands of missing and non-missing values (cells) which means that data missingness displays monotonicity (see IBM SPSS Missing Values 20, pp. 48-49). Individuals having missing values on a given variable will also have missing values on other, subsequent variables. Similarly, monotonicity is apparent when a variable is observed for an individual, the other, previous variables are also observed for that individual. Say, we have 6 variables, var1 has no missing, 10% people are missing on var2 but also on all other variables, 10% additional are missing on var3 but also on the next variables, 10% additional are missing on var4 but also on var5 and var6, and so on. The opposite is an arbitrary missing pattern which involves impossibility of reordering the variables to form a monotonic pattern. To be sure, here’s an overview of missing data patterns, from Huisman (2008) :


Compare with what I get, below. At the bottom of this picture, there seems to be a tendency for monotonicity. But from a global perspective, the justification for a monotone imputation method is not clear to me.
SPSS offers the Fully Conditional Specification (FCS) method, also known as chained equations (MICE) or sequential regression (SRMI), which fits an univariate (single dependent variable) model using all other available variables in the model as predictors and then imputes missing values for the variable being fit. FCS is known as being very flexible, does not rely on the assumption of multivariate normality. FCS uses a specific univariate model per variable, and is a sort of variable-by-variable imputation, i.e., specifying linear regression for continuous var., logistic regression for binary var., ordinal logistic regression for categorical var. In SPSS, the FCS employs Markov Chain Monte Carlo (MCMC) method; further reading, see Huisman (2011). More precisely, it employs the Gibbs Sampler; such method, or FCS in general, according to van Buuren et al. (2006) is quite robust even when MAR assumption is violated, although their study needs to be replicated, as the authors said. The MCMC uses simulation from a Bayesian prediction distribution for normal data. Allison (2009) describes it as follows : “After generating predicted values based on the linear regressions, random draws are made from the (simulated) error distribution for each regression equation. These random ‘errors’ are added to the predicted values for each individual to produce the imputed values. The addition of this random variation compensates for the downward bias in variance estimates that usually results from deterministic imputation methods.” (p. 82).
The FCS differs from the multivariate normal imputation method (MVN or MVNI) also known as joint modeling (JM) in which all variables in the imputation model jointly follow a multivariate normal distribution. MVN uses a common model for all variables, multivariate normal for continuous var., multinomial/loglinear for categorical var., general location for a mixture of continuous and categorical var., but encounters difficulty when the included variables have different scale types (continuous, binary, …) whereas FCS can accomodate it. Despite MVN being more restrictive than FCS (e.g., the use of binary var. and categorical var. makes the normality assumption even more unlikely), Lee & Carlin (2009) found both methods perform equally well even though their imputation model included binary and categorical variables. Unfortunately, van Buuren (2007) found evidence of bias related with JM approach under MVN when normality does not hold. It is not all clear under which condition MVN is robust.
In the present data, I noticed that the selection of monotonic method instead of MCMC is not effective and SPSS send us an error message like “the missing value pattern in the data is not monotone in the specified variable order”. In this way, we can easily choose which method we really need. See Starkweather (2012) and Howell (2012) for the procedure in SPSS.
When using MCMC, Starkweather and Ludwig-Mayerhofer have suggested to increase the maximum iteration from the default value of 10 to 100, so as to increase the likelihood of attaining convergence (when the MCMC chain reaches stability – meaning the estimates are no longer fluctuating more than some arbitrarily small amount). That means 100 iterations will be run for each imputation. Because the default value is too low, I wouldn’t recommend the “auto” option. But Allison (2002, p. 53) stated however that the marginal return is likely to be too small for most applications to be of concern.
Then, we are given two model types for scale variables, Linear Regression (by default) or Predictive Mean Matching. PMM still uses regression, but the resulting predicted values are adjusted to match the closest (actual, existing) value in the data (i.e. the nearest non-missing value to the predicted value). It helps ensuring that the imputed values are reasonable (within the range of the original data). Given the apparent advantage of PMM (such as, avoiding extreme outliers in imputed values) over the default option, I select PMM with my MCMC imputation method.
The next step is to go to “Impute Missing Data Values” in order to create the imputed data set. All the variables in the model have to be selected. If the missing pattern is arbitrary, we go to Method, Custom, and click on “Fully conditional specification (MCMC)” with max iterations at 100, preferably. Nonetheless, MCMC works well for both monotonic and arbitrary patterns. If we don’t really know for sure about the missing pattern, we can let SPSS decide. It will choose the monotone method for a monotonic pattern and MCMC method otherwise (in this case, the default number of iteration would be too low). Concretely, SPSS (like AMOS) will create a new data set (with new dataset name). The entire procedure is explained in this webpage and this video. See also IBM SPSS Missing Values 20 (pp. 17-23).
When using FCS method, we must also request a dataset for the iteration history. After this, we should plot the mean and standard deviation of the imputed values on the iterations, for each variable separately, splitted by the imputation number. See the manual SPSS missing values 20 (pp. 64-67) for the procedure of FCS convergence charts. The purpose of this plot is to look for patterns in the lines. There should not be any, and they will look suitably “random”.
Last thing, it is extremely important not to forget to change the measurement level of the variables. For example, mom_educ and dad_educ were initially configured as “nominal” while imputation in SPSS only works with “scale” variables, not with “nominal” or “ordinal” measure. We simply have to re-configure these in the SPSS data editor window. Otherwise, SPSS gives such message “The imputation model for [variable] contains more than 100 parameters. No missing values will be imputed.” See here.

In the data editor, at the upper right, we see a list of numbers below “Original Data” going from 1 to 5. They represent the number of imputations (5 being the default number on SPSS) because it’s a multiple (not single) imputation. The data has been imputed 5 times, each time giving us with different imputed values. If we had 50 individuals cases (i.e., 50 rows), clicking on 1 will bring us to the 51th row and the 50 following rows, clicking on 2 will bring us on the 101th row and the 50 following rows, and so on. Finally, the yellow shaded cells show the newly created values.
This new dataset is very special. If we perform an analysis using the new dataset, for example a mean comparison of GPA score with gender group, we will be given a table divided into 7 parts. First, we have the mean value (and other stats requested on SPSS) for the original data, second, the mean for each of the five imputed data, and finally the mean for the pooled of the five imputed data. And the pooled (i.e., aggregated) result is the only one we are interested in when performing analyses on SPSS, unless we want to apply Rubin’s formula. We can also use the SPLIT FILE function with the variable “imputation_” in order to get separate results for each stacked data.
There is another method, called Expectation-Maximization, which overcomes some of the limitations of the mean and regression substitution methods such as the preservation of the relationship between variables and lower underestimation of standard errors, even if it is still present in EM. It proceeds in 2 steps. The E-step finds the distribution for the missing data based on the known values for the observed data and the current estimates of the parameters; and the M-step substitutes the missing data with the expected values. This two-step process iterates (default value=25 in SPSS) until changes in expected values from iteration to iteration become negligible. EM assumes a multivariate normal model of imputation and has a tendency to underestimate standard errors due to the absence of a component of randomness in the procedure. Unfortunately in SPSS, there is no way we can create a clustered data file with EM method. We can only create several separate files.
To perform EM, go to “Missing Value Analysis” and put the ID variable in Case Labels, put the variables of interest in Quantitative or Categorical Variables depending on the nature of the variable (e.g., scale or nominal) and select the “EM” box. There is also an EM blue button which we need to look at, and then we click on “save completed data” and name the new data set. When we click on OK, the output provides us with several tables, notably “EM means”, “EM covariances”, “EM correlations” with the associated p-value from χ² statistics. This is a test of the MAR assumption known as Little’s Missing Completely at Random (MCAR) Test. Because the null hypothesis was that the data are missing completely at random, a p-value less than 0.05 indicates violation of MCAR. As always, the χ² is sensitive to sample size and with large N we are likely to have a low p-value, easily lower than 0.05 due to high power of detecting even a small deviation from the null hypothesis, as I noticed when performing this test which appears completely worthless.
Another method, initially not included in SPSS package, is the Hot Deck. This is the best-known approach to nonparametric imputation (although it does not work well with continuous/quantitative variables) and this means it avoids the assumption of data normality. The hot deck procedure sorts the rows (i.e. respondents) of a data file within a set of variables, called the “deck” (or adjustment cells). The procedure involves replacing missing values of one or more variables for a nonrespondent (donees) with observed values from a respondent (donors) that is similar to the non-respondent with respect to characteristics observed by both cases; for example, both of them have variables x1, x2, x3, x4 with, say, respectively, values of 6, 5, 4, 4, but the donor has x5 with value of 2 while the donee has no value in x5, and so the hot deck will give him a value of 2 as well. In some versions, the donor is selected randomly from a set of potential donors. In some other versions, a single donor is identified and values are imputed from that case, usually the nearest neighbor hot deck. Among the benefits of hot deck, the imputations will not be outside the range of possible values. This method performs less well when the ratio of variables (used for imputation process) to sample size becomes larger, and should probably be avoided in small data because it seems difficult to find donors with good matching in small data, and has also the problem of omitting random variations in the imputation process. Even when multiple imputation is performed, the variance in the pooling process is still underestimated although some other procedures (e.g., Bayesian Bootstrap) can overcome this problem (Andridge & Little, 2010). Myers (2011) gives the “SPSS Hot deck macro” for creating this command for SPSS software. Just copy-paste it as it is. See also figure 3 for illustration of the procedure.
The PMM (semi-parametric) method available in SPSS resembles hot deck in many instances but because it uses regression to fill the data, it assumes distributional normality but has the advantage that it works better for continuous variables. It still adds a random component in the imputation process, preserves data distribution and multivariate relationship between variables. Andridge & Little (2010) argue about the advantages of PMM over hot decks.
Like hot deck, PMM is recommended for monotone missing data, and it works less well with an arbitrary missing pattern, which is probably what we have presently. It is possible that the method I used is not optimal, and in this case I should have selected MCMC with linear regression method, not PMM. Nonetheless, regarding the bivariate correlations of all the variables used, the pooled average does not diverge so much from the original data. Most often, the cells differs very little, with correlations differing by between ±0.000 and ±0.015. In some cases, the difference was ±0.020 or ±0.030. Exceptionally, some extreme cases have been detected, with cells where the difference was about ±0.050. Even my SEM analyses using MI look similar to those obtained with ML (see below). Moreover, linear regression and PMM produce the same results (see XLS). So generally, it seems that PMM does not perform badly in preserving the correlations.
b) Multiple imputation on AMOS.
In AMOS graphics, one needs to select and put the selection of variables we want to impute. Unlike SPSS, AMOS can impute latent variables. All it needs is to construct the measurement model with the observed and latent var.
In Amos (see, User’s Guide, ch. 30, pp. 461-468), three options are proposed : 1) regression imputation, 2) stochastic (i.e., aleatory) regression imputation (also used in SPSS), 3) Bayesian imputation. The first (1) fits the model using ML and then the model parameters are set equal to their maximum likelihood estimates, and linear regression is used to predict the unobserved values for each case as a linear combination of the observed values for that same case. Predicted values are then plugged in for the missing values. The second (2) imputes values for each case by drawing randomly from the conditional distribution of the missing values given the observed values, with the unknown model parameters set equal to their maximum likelihood estimates. Because of the random element in stochastic regression imputation, repeating the imputation process many times will produce a different dataset each time. Thus, in standard regression, the operation looks X^i=b0+b1Zi while in the stochastic we have X^i=b0+b1Zi+ui where ui is the random variation. The addition of the random error avoids the underestimation of standard errors. The third (3) resembles stochastic except that it considers model parameters as stochastic variables and not single estimates of unknown constants.
The first option 1) is a single imputation and should not be used. 2) and 3) propose multiple imputations, could be configured using the box “number of completed dataset” which has a default value of 5. It designates the number of imputed data we want to generate before averaging them. Make sure that the box “single output file” is checked. Because checking “multiple output file” will create 5 different datasets, one for each imputation completed. With single file, the datasets will be stacked together with a variable “imputation_” having 5 values; say, we have data for 50 subjects, thus, rows 1-50 belong to the value 0 in the variable “imputation_”. Then, rows 51-100 belong to 1 in the variable “imputation_”, rows 101-150 belong to 2, and so on. While multiple files create 5 files with each 50 rows, the single file creates 1 file with 250 rows.
Byrne (2010, p. 357) while arguing that mean imputation method is flawed said that the regression imputation also has its limitations. Nonetheless, stochastic regression imputation is still superior than regression imputation. This seems to be the best option available in AMOS. But it is probably not recommended to conduct imputation with AMOS especially when SPSS proposes more (flexible) options.
Now, we can look at the newly created data, which only contains the variables we need for our CFA-SEM analysis. Obviously, it lacks the grouping variables (e.g., “race” in the present case). We can simply copy-paste the variable’s column from the original data set to this newly created data set, or to merge these data sets (->Data, ->Merge Files, ->Add Variables, move the “excluded” variables into the “key variables” box, click on ‘Match cases on key variables in sorted files’ and ‘Both files provide cases’ and OK). When this is done, save it in a computer’s folder before closing the window. There is no need to be concerned by the possibility that the ID numbers (i.e., raws) could have been rearranged in the process of imputation, that is, IDs are no longer ordered in the same way. In fact, SPSS/AMOS keeps the row values in the original order. So, copy pasting does not pose any problem.
2.2.4. Distribution normality and Data cleaning.
a) Checking variables’ normality.
Violation of data normality, whether univariate or multivariate, is a threat even for SEM. This can cause model misfit, although not systematically so (Hayduk et al., 2007, p. 847). And even more. Specifically, skewness affects test of means whereas kurtosis affects test of variances and covariances (Byrne, 2010, p. 103). We can check univariate normality by looking at skewness and kurtosis in SPSS. Both skewness and kurtosis should be divided by their associated standard error, a (positive or negative) value should not be greater than absolute 1.96 in small samples, no greater than absolute 2.58 in large sample (200 or more) but in very large sample this test must be ignored (Field, 2009, pp. 137-139). Indeed, when sample size increases, the standard error decreases. For example, the distribution normality of GPA_overall was perfect in the black sample (N=1132, in the original data set) with respect to the histogram, but skewness and its standard error had values of -0.279 and 0.073, in other words a ratio of -3.82, which clearly departs from an absolute value of 2.58. Nevertheless, a rule of thumb is always arbitrary and, in our case, with samples generally larger than 1000, we don’t use this test.
Now, the concept of multivariate normality is somewhat different. The univariate (outlier) is an extreme score on a single variable whereas multivariate (outlier) is an extreme score on two or more variables. Byrne (2010, p. 103) informs us that univariate is a necessary but not sufficient condition for multivariate normality. In AMOS, we can easily display the “tests for normality and outliers” in the “Analysis Properties” box. Unfortunately, AMOS refuses to perform this test when we have missing values, a condition that applies to all (survey) data sets. In his website, DeCarlo gives SPSS macro for the multivariate test of skew and kurtosis, but I don’t know how that works.
Hopefully, it is still possible to deal with missing data in AMOS by using the “multiple imputation” method. This consists in replacing missing values by substituted, newly created values based on information from the existing data. At the end, we can assess multivariate normality.
We are given the skew and kurtosis univariate values (with their C.R.) for each observed variables. The absolute univariate kurtosis value greater than 7.0 is indicative of early deviation from normality (Byrne, 2010, pp. 103-104), but a value of 10 is problematic and larger than 20 it becomes extreme (Weston & Gore, 2006, p. 735). An absolute univariate skew value should be no greater than 2 (Newsom, 2012) and a value larger than 3 is extreme. With regard to the C.R. (skewness or kurtosis divided by standard error of skewness or kurtosis), it should not be trusted, because of the standard error being too small in large sample sizes. At the very least, we can still compare the C.R. among the variables even if it would be more meaningful to simply look at the univariate kurtosis value. Concerning the multivariate kurtosis critical ratio, C.R., also called Mardia’s normalized coefficient because it is distributed as a z-test, it should not be greater than 5.0. Concerning the multivariate kurtosis, or simply Mardia’s coefficient of multivariate kurtosis, Bollen (1989) proposes that if the kurtosis value is lower than p*(p+2), where p is the number of observed variables, then there is multivariate normality.
AMOS test for normality also gives us the Mahalanobis d-squared values (i.e., the observations farthest from the centroid) for each individual case. The values are listed and start from the highest d² until the lowest d² is reached. A value that is largely distant from the next other value(s) is likely to be a strong outlier at either one of the ends. An illustration that worths 1000 words is given in Byrne (2010, p. 341). As always, the p values associated with the d² values are of no value. With large sample sizes, they will always be 0.000. Gao et al. (2008) mention the possibility of deleting outliers to help achieving multivariate normality but that a large amount of deleted cases would hurt generalizability.
When AMOS lists the number associated with the individual case, this number does not refer to the ID value of the survey data, but the case sorting from lowest ID to highest ID. The column in blue, below :

The mismatch between ID and the case sorting is probably due to the syntax I used for creating the imputed data (filter by race variable). So, for example, the case value (outlier) 1173 suggested by Mahalanobis distance, in my imputed dataset, refers in reality to the number in the blue column, not 7781 under the variable column R0000100 that represents the ID number in NLSY97. Because of this, we need to be careful. Delete outliers by beginning from the highest case value, to the lowest case value. Otherwise, the case ordering would be re-arranged.
For the univariate test, in SPSS, I have used a complete EXPLORE (in ‘descriptive statistics’ option) analysis for all the variables. It shows skewness and kurtosis values with their respective standard error, and as we noted earlier, this test can be ignored. It is probably more meaningful to look at the normal Q-Q plot (violation of normality is evidenced if the dots deviate from the reference fitted line) and detrended normal Q-Q plot (which has the same purpose but just allows us to check the pattern from another angle). Finally, EXPLORE will display boxplots with individual cases that could be outliers. Also displayed as test of normality is the Kolmogorov-Smirnov but this test is flawed and should probably never be used (Erceg-Hurn & Mirosevich, 2008, p. 594).
Regarding ASVAB subtests, normality holds, although AO departs (but not too seriously) from normality. Generally, when the dots depart from the reference fitted line, they do it at the extremities (lower or upper) of the graph. The same applies for Mom_Educ, Dad_Educ and SQRT_parental_income, with no serious violation of normality. Given the boxplots, there was no strong outliers in any of these variables, except Mom_Educ and Dad_Educ (in the black sample only) because there were too much people with 12 years of education and few people with less or more than 12 years, which produced a histogram with an impressive peak at the middle. In any case, this general pattern is quite similar for black, hispanic and white samples. We can conclude there is no obvious deviation from normality given those tests.
Before leaving this topic, always keep in mind that EXPLORE analysis must be performed with option “exclude cases pairwise” or otherwise a large amount of cases in all of the selected variables could be ignored in the process.
b) Choosing SEM methods.
Parameters (i.e., error terms, regression weights or factor loadings, structural (path) coefficients, variance and covariance of independent variables) are estimated with maximum likelihood (ML) method, which attempts to maximize the chance (probability) that obtained values of the dependent variable will be correctly predicted. For a thorough description, go here. ML is chosen because it is known to yield the most accurate results. Other methods include Generalized Least Squares (GLS) and unweighted least square (ULS; requires that all observed variables have the same scale) which minimizes the squared deviations between values of the criterion variable and those predicted by the model. Both ML and GLS assume (multivariate) distribution normality with continuous variables, but other methods like scale-free least squares, and asymptotically distribution-free (ADF), do not assume normality of data. ML estimates are not seriously biased when multivariate normality is not respected (Mueller & Hancock, 2007, pp. 504-505), if sample size is large enough, or “(if the proper covariance or correlation matrix is analyzed, that is, Pearson for continuous variables, polychoric, or polyserial correlation when categorical variable is involved) but their estimated standard errors will likely be underestimated and the model chi-square statistic will be inflated.” (Lei & Wu, 2007, p. 43).
Of use presently is ML, and then Multiple Imputation (MI) for comparison matter, because we have incomplete data (the total N subjects having SES parental income and education is much lower than total N subjects having ASVAB) and because AMOS does not allow other methods to run when we have missing values. The ML method, consisting in producing estimate for parameters of incomplete variables based on information of the observed data, yields unbiased estimates under the assumption that data is missing at random (MAR; missingness correlated with observed scores but not missing scores) or completely at random (MCAR; missingness not correlated with either observed or missing scores). Hopefully, it seems that ML tends to reduce bias even when MAR condition is not fully satisfied (Byrne, 2010, pp. 358-359). It is in fact the least biased method when MAR is violated. To note, MAR and MCAR are usually called ignorable missing whereas MNAR is called non-ignorable missing. On AMOS, clicking on “estimate means and intercepts” on “Analysis Properties” gives us the full information ML, or FIML.
2.2.5. Bootstrapping in structural equation modeling.
As far as I know, this technique is rarely used in research papers. Bootstrap consists in creating a sampling distribution that allows us to estimate standard errors and create confidence intervals without satisfying the assumption of multivariate normality (note : a path having confidence interval that includes zero in its range would mean that the hypothesis of nonzero value for this parameter is rejected). To be clear, imagine our original sample has n=500 cases or subjects. We use bootstrap to create, say, 1000 samples consisting of n=500 cases by randomly selecting cases with replacement from the original sample. In those bootstrap samples of same size, some individuals can be selected several times, and some others less often, or maybe not at all. This causes each sample to randomly depart from the original sample. In a normal sample (given n=10) we may have X_mean = (x1, x2, x3, x4, x5, x6, x7, x8, x9, x10) / 10. Whereas in any single bootstrap resampling we may have X_mean = (x1, x2, x3, x3, x3, x3, x7, x8, x8, x10) / 10. Or any other combination. In the former, one case can only result in one draw. In the latter, one case can result in several draws. Given 1000 bootstrap samples, we will get the average mean value across the 1000 samples.
Besides bootstrap approach, some statistics have been used to evaluate the significance of a mediation effect. Sobel test is sometimes reported but if it assumes normality, oftentimes violated, such test may not be accurate (Cheung & Lau, 2008). Another statistic is the Satorra-Bentler scaled Chi-Square that controls for non-normality, “which adjusts downward the value of χ² from standard ML estimation by an amount that reflects the degree of kurtosis” (Kline, 2011, p. 177) although Chi-Square based statistics are known to be sensitive to N. AMOS does not provide S-B χ² but bootstrap is even more effective in dealing with non-normality. See here.
Bootstrap great advantage is to be a non-parametric approach, meaning that it deals with non-normality of the data. It seems more reliable with large sample size and generally is not recommended with N<100. See Byrne (2010, ch. 12, pp. 329-352) for a detailed demonstration using AMOS. Note that Byrne informs us that bootstrap standard errors seem to be more biased than those from the standard ML method when data is multivariate normal, but less biased when data is not multivariate normal.
There exists two types of bootstrapping. The naïve method, for obtaining parameter estimates, confidence intervals, standard errors, and the Bollen-Stine method, for obtaining the p value for the model fit statistics. Concerning the p value for model fit, Sharma & Kim (2013, pp. 2-3) noted that bootstrap samples sometimes don’t represent the population. Under the naïve approach, the mean of the bootstrap population (i.e., the average of the observed sample) is not likely to be equal to zero. In this case, bootstrap samples are drawn from a population for which the null hypothesis (H0) does not hold regardless of whether H0 holds for the unknown population from the original sample was drawn. Hence the bootstrap values of the test statistic are likely to reject H0 too often. The Bollen-Stine method circumvents this problem by centering the mean of the bootstrapped population to be zero.
If Bollen-Stine provides correct p-values for χ² statistics to assess the overall model fit, remember that Bollen-Stine p-value is still inflated by larger sample sizes. We don’t need to take χ² too seriously. When we use AMOS to perform B-S bootstrap, we are provided with an output like this :
The model fit better in 1000 bootstrap samples.
It fit about equally well in 0 bootstrap samples.
It fit worse or failed to fit in 0 bootstrap samples.
Testing the null hypothesis that the model is correct, Bollen-Stine bootstrap p = .001
This Bollen-Stine p-value is calculated as how many times the model chi-square for bootstrap samples is higher (i.e., “fit worse”) than the observed data chi-square, or (0+1)/1000=0.001 if we use 1000 samples (see here). Non-significant value (>0.05) means good model fit. As always, p-value is highly sensitive to sample size, so this number in itself is not very useful. We just need to focuse on the naïve method.
AMOS provides us with bias-corrected confidence intervals; this approach is more accurate for parameters whose estimates’ sampling distributions are asymmetric. The “bias corrected CI” and “Bollen-Stine bootstrap” can be both selected but AMOS won’t estimate both on the same run. Just choose one of them. The main problem is that AMOS won’t run the bootstrap if we have missing values. Therefore, I apply the multiple imputation, and then bootstrapping each of the 5 imputed data sets. That means running the analysis 5 times.
2.2.6. Modification indices and correlated residuals.
There is also the possibility to improve model fit through Modification Indices in AMOS. The program produces a list of all possible covariances and paths that are susceptible to improve model fit. This means that adding a path or a covariance will greatly reduce the discrepancy between the actual model and the data. But generally, with survey data, we have missing values (i.e., observed cases). AMOS won’t run even if ML method is chosen. Therefore, we can use multiple imputation. Or we can use a sort of listwise deletion. SPSS can create variables having no missing values. This is easily done using the command DO IF (NOT MISSING(variable01)) AND (NOT MISSING(variable02)) … END DO IF. Suppose we want data for all of the 12 ASVAB subtests. We compute a new subtest variable on the condition that it also contains data for all the remaining subtests. Alternatively, if we want to do SEM analyses using parental income, education, occupation, and other demographic variables, we need to add all these variables in the DO IF (NOT MISSING(variable_x)) command. We do this for each variables, including all other variables we need under the “not missing” condition.
The question of whether researchers should allow correlated residuals in SEM models is debated. According to Hermida et al., theoretical justification for such practice is generally not provided. The probability of correlating the residuals seems to be related with the failure to attain sufficient model fit (e.g., RMSEA larger than 0.10 or CFI lower than 0.90). Presently in the case of NLSY-ASVAB, Coyle (2008, 2011, 2013) has used the method consisting in correlating measurement errors (or residuals) even among different latent factors. He argues that it improves the model fit. This is not surprising if making the model more complex by adding more covariances or paths will approximate at the end the model fit in a saturated model.
When adding parameters according to what modification indices suggest, I notice indeed a non-trivial model fit improvement, but unless there is a reasonable theoretical reason of doing this, I allow the residuals to be uncorrelated. Otherwise it would likely cause identification problems regarding the latent(s) factor(s) involved when we end up with good model fit but also with latent variables which do not accurately represent the theoretical constructs we were aiming to build. Besides, even within a single latent factor, the correlated residuals can suggest the presence of another (unmeasured) latent factor, and hence multidimensionality, because the key concept of correlated errors is that the unique variances of the indicator variables measure and share something in common other than the latent factor they belong to. But this, alone, can justify correlated errors. Nonetheless, if these correlations have no theoretical or practical significance, they should be ignored. These secondary factor loadings (or error term correlations) can be called secondary relationships. When these secondary relationships are excluded from the model, we refer to parsimony error, i.e., those excluded (non-zero) relationships having no theoretical interest. See Cheung & Rensvold (2001, p. 239).
MacCallum et al. (1992) explain that most researchers do not offer interpretations for model modification. They even cite Steiger (1990) who suspected that the percentage of researchers able to provide theoretical justification for freeing a parameter was near zero. They also point out the common problem of allowing covariance among error terms. Apparently, researchers tend to have it both ways : they want well-fitted model but not the responsibility of interpreting changes made to achieve this good fit.
Lei & Wu (2007) explain the needs to cross-validate this result and, to illustrate, provide some tests based on model modification. As demonstrated by MacCallum et al. (1992), results obtained from model modifications tend to be inconsistent across repeated samples, with cross-validation results behaving erratically. Such outcome is likely to be driven by the characteristics of the particular sample, and so, the risk of capitalization on chance is apparent. This renders replication very unlikely.
Another danger is the ignorance of the impact of correlated residuals on the changes in interpretation of the latent factors measured by the set of observed variables having their errors correlated (or not). Cole et al. (2007, pp. 383-387) discuss this issue and present an example with a latent variable named “child depression” measured by one (or two) child-report (C) measures and two (or one) parent-report (P) measures, which means that child depression is assessed via 2 different methods but of unequal number of variables per method. Controlling for shared method variance changes the nature of the latent factor, as they wrote “In Model 1a, the latent variable is child depression per se, as all covariation due to method has been statistically controlled. In Model 2a, self-report method covariation between C1 and C2 has not been controlled. The nature of the latent variable must change to account for this uncontrolled source of covariance. The larger loadings of C1 and C2 suggest that the latent variable might better be called self-reported child depression. In Model 2b, parent-report method covariation between P1 and P2 has not been controlled. Consequently, the loadings of P1 and P2 increase, and the latent variable transforms into a parent-reported child depression factor.” (p. 384). They conclude that “In reality, it is the construct that has changed, not the measures.” (p. 387). In other words, when omitting to control for method covariance, we get a biased latent factor, favorably biased towards the methods for which we have relatively more variables. In Cole et al. (2007, p. 386), we see from their Figure 3, Model 3a versus 3b, that the observed variables having their errors correlated have seen their loadings on the factor diminished. This was also what I have noticed in my ACT-g, after controlling for the residuals of ACT-english and ACT-reading.
To conclude, Cole et al. (2007) are not saying we should or we should not correlate the error terms, but that we must interpret the latent factor properly, according to the presence or absence of correlated errors.
Given this discussion, I allow MOM_EDUC and DAD_EDUC residuals to be correlated. But maybe it is not necessarily the best move to give more weight on family income, in doing so, because income has less reliability, varying much more over time, let alone the fact that education level does no reflect perfectly the amount of earnings in real life. With regard to ACT-g, I also assume that the variance of ACT-eng and ACT-read not caused (i.e., the residuals) by the latent ACT factor is not unique to either of these variables, so their residuals have been correlated.
2.2.7. Heywood anomaly.
The so-called “Heywood case” manifests itself in out-of-range estimates. For example, a standardized value greater than +1 or lower than -1. A negative error variance is also seen as Heywood case. Outside the SEM topic, we can also detect some Heywood cases when conducting factor analysis (e.g., Maximum-Likelihood) with communalities greater than 1. In this situation, the solution must be interpreted with caution (SPSS usually gives a warning message). When some factor loadings in these factor analyses were larger than 1, it can be considered as Heywood cases.
Negative (error) variances may occur with smaller samples, for example, because of random sampling variability when the population value is near zero (Newsom, 2012). When the R² becomes greater than 1.00, it means the error variance is negative (AMOS output “Notes for Model” shows us when it encounters improper solutions with, e.g., negative error variances). This could be reflected by overcorrection for unreliability, which leaves too little variance to be explained in the construct. In constrast, a zero error variance in an endogenous variable must imply that a dependent variable is explained perfectly by the set of predictors. When standardized regression weights are out of normal bounds, that could be a sign that two variables behave as if they were identical. A very high correlation between factors may occur when many observed variables have loadings on multiple factors (Bentler & Chou, 1987, p. 106). Generally, improper solution can result from outliers or influential cases, or violation of regression assumptions (e.g., heteroscedasticity), and even with small sample sizes (Sharma et al., 2005, p. 937) combined (or not) with small factor loadings. See also Bentler & Chou (1987, pp. 104-105).
Lei & Wu (2007) stated the following : “The estimation of a model may fail to converge or the solutions provided may be improper. In the former case, SEM software programs generally stop the estimation process and issue an error message or warning. In the latter, parameter estimates are provided but they are not interpretable because some estimates are out of range (e.g., correlation greater than 1, negative variance). These problems may result if a model is ill specified (e.g., the model is not identified), the data are problematic (e.g., sample size is too small, variables are highly correlated, etc.), or both. Multicollinearity occurs when some variables are linearly dependent or strongly correlated (e.g., bivariate correlation > .85). It causes similar estimation problems in SEM as in multiple regression. Methods for detecting and solving multicollinearity problems established for multiple regression can also be applied in SEM.” (p. 36). See also Kenny (2011).
If Heywood cases have been caused by multicollinearity, the estimates are still unbiased but the relative strength of independent variables becomes unreliable. For instance, in the standardized solution, the estimates were assigned a metric of 1, which means that regression paths range from -1;+1 but when we have multicollinearity, the regression weights between some two variables should be close to unity. If those variables are used to predict another variable, separate regression weights are difficult to compute and we may result with out-of-range estimate values. Also, these paths would have larger standard errors and covariances. It is even possible that the variance of the dependent (endogenous) variable is negative due to this.
Byrne (2010, 187-192) shows an empirical example where some standardized path regressions are out-of-range -1;+1. As Byrne declares, the very high factor correlation (0.96) between the latent variables in question could have been the explanation. Byrne proposes two solutions : 1) completely delete one factor with the related observed variables 2) instead of having 2 sets of observed variables loaded on two separate factors, form a new factor with all these observed variables loaded on this single factor.
Nonetheless, if measurement error attenuates correlations (e.g., among exogenous var.) and if (SEM) latent variable approach controls for them, it follows that SEM makes multicollinearity to appear where it previously has not been a problem (Grewal et al., 2004).
Grewal et al. (2004) also stated that high reliability of variables can tolerate high multicollinearity, and also that correction for attenuation (or measurement error) will not increase the correlation between latent constructs to unacceptably high levels. Hopefully, the measures used presently are highly reliable. Furthermore, they add : “It should be noted, however, that high levels of multicollinearity may be less apparent in SEM than regression. Because of the attenuation created by measurement error, the cross-construct correlations among indicators will be lower than the actual level of multicollinearity (i.e., correlations among the exogenous constructs).” (p. 526). More interesting is that the deleterious effect of multicollinearity is offset if sample size is large and if the variance (R²) of the dependent variable explained by the independent variables is high. Remember that latent variables approach normally makes R² to increase while at the same time it favors multicollinearity between latent variables.
2.2.8. Sampling weight.
We can use the “customized weights” available in this webpage; survey year 1997, 1999, 2010, and choose “all” of the selected years, for a truly longitudinal weight (choosing “all” and “any or all” produces the same numbers given several tests of regressions). There is no option in AMOS for the inclusion of weight variables for estimating parameters in CFA or SEM models. I am aware of only two ways for dealing with this problem :
1) In SPSS, activate your weight. Activate your filter, by race. Then, run the SPSS syntax displayed in this webpage with the relevant variables in your data set. The syntax command LIST will define a raw data file by assigning names and formats to each variable in the file, and MCONVERT will convert a correlation matrix into a covariance matrix or vice versa. Save the file that is created, and use it as input for AMOS. The rows must contain means, SD, variances, covariances, and N.
2) Include the weight variable as a covariate in the imputations with the variables for which missing values have to be imputed (SPSS -> “impute missing data values” -> “analysis weight”). Cases with negative or zero weight are excluded. See Carpenter (2011, 2012), Andridge & Little (2010, 2011) for further discussion.
I haven’t use any weights in the imputation process. That won’t distort the result, given the great similitude of estimates in several multiple regressions I performed on SPSS, with and without weights.
3. Results.
3.1. CFA. Measurement model.
a) Procedure.
Before going to CFA, we need to perform some Exploratory Factor Analyses (EFA). This is simply done by using the “dimension reduction” process, option “principal axis factor” because PCA would not be optimal with rotated solution, according to Costello & Osborne (2005, p. 2). These authors said that maximum-likelihood and PAF generally give the best results but ML is only recommended if we are certain that (multivariate) distribution normality is respected, a condition that seems to be rarely met in real data. Given this, PAF has been selected.
Possible rotations include Varimax, Quartimax, Equamax, Promax, Direct Oblimin. Field (2009, p. 644) says that Quartimax attempts to maximize the spread of factor loadings for a variable across all factors whereas Varimax attempts to maximize the dispersion of loadings within factors. Equamax is the hybrid of the two. If we need oblique rotation, we can choose Oblimin or Promax. Oblimin proceeds by finding rotation of the initial factors that will minimize the cross products of the factor loadings, many of them becoming close to zero. Promax rotates a solution that has been previously rotated with orthogonal methods (Varimax, in fact) and adjusts axes in such a manner as to make those variables with small loadings on a dimension to be near zero. If factors were independent, they should be uncorrelated and orthogonal would produce similar results as oblique rotation. Field recommends Varimax if we want more interpretable, independent clusters of factors.
But these factors in ASVAB are assumed to be correlated and an orthogonal factor rotation would reveal a good correlation (in the table Factor Correlation Matrix) between the factors anyway. Thus I have opted for the oblique rotation Promax, often recommended for giving a better oblique simple structure (Coffey, 2006), which has a Kappa value of 4 in SPSS. This was the default option because it generally provides a good solution (see here).
Usually (at least in SPSS) the default “extraction” option for factor analysis is set at factors greater than 1.0 eigenvalue. Costello & Osborne (2005, p. 3) argue this is the least accurate among the methods. They recommend to be cautious about the presence of cross-loadings, in which cases we might think of removing the “anomalous” variables. Any variable with loading lower than 0.30 or cross-loading larger than 0.30 can be excluded. Again, these cut-offs are totally arbitrary. But a coefficient of 0.30 for both is generally what researchers propose, as exclusion criteria.
In the displayed SPSS output, we are provided with several tables, notably a pattern and a structure matrix. Because we want the regression (not correlation) coefficient of, we choose the pattern matrix (Field, 2009, pp. 631, 666, 669). We want to transpose it to AMOS. To ease the process, James Gaskin has created a special plugin for doing it. Go to his website and click on “Amos EFA-CFA Plugin” on the left panel, click on this dll file and select “Unblock” and finally move the dll file to the Amos folder “plugins” with the other dll. This video summarizes the procedure if my explanation wasn’t clear enough. When it is done, the “Plugins” option in AMOS Graphics now has a new function labeled “Pattern Matrix Model Builder”. It allows us to directly copy-paste the pattern matrix (e.g., directly from SPSS output) and to create the measurement model diagram accordingly.
Because it is possible given certain version of SPSS that the displayed numbers in the ouput may have a comma instead of a dot, we can correct for this using the following syntax :
SET LOCALE="en_US.windows-1252".
b) Results.
The main problem I came through is the presence of numerous cross-loadings and more threatening, the pattern of loadings on the latent factors that differs somewhat across all between-race comparisons. That means configural invariance (equivalence) is already not very strong, but not apparently violated. Conducting MGCFA test gives CFI and RMSEA values >0.90 and <0.10, respectively, although intercepts invariance is strongly violated for any group comparison. But I will dedicate a post on this topic later.
The XLS file (see below) displays the model fit indices for first-order g model, second-order g with 3 group and 4 group factors, with and without cross-loadings when one or more subtests load almost equally well on several factors when these loadings were meaningful (e.g., around 0.30).
It has been difficult to choose among the g-models. For instance, the 3-group g model seem to have a slight advantage over 4-group g model in terms of fit but one of the group factor labeled “school” which comprised verbal and math subtests (as well as some technical knowledge subtests) has a factor loading on g that is greater than 1 for all racial groups. The 4-group g model was the more coherent. The first-order g model has the worse fit perhaps because multiple subtests of verbal, math, speed and technical skills suggest the presence of factors summarizing these variables, before g itself (Little et al., 2002, p. 170).
Considering the non-use (or fewer) of cross-loadings, it is possible to follow authors’ recommendations from their own CFAs. Coyle et al. (2008, 2011), Ree & Carretta (1994) produced an ASVAB 3-group g model (what they call Vernon-like model) with scholastic factor (AR, PC, WK, MK), speed (NO, CS) and technical factor (GS, AI, SI, MC, EI) and also a 4-group g model with verbal/technical (GS, WK, PC, EI), technical (AI, SI, MC, EI), math (AR, MK, MC) and speed (NO, CS). Deary et al. (2007) also employed a 4-group g model with verbal (GS, PC, WK), math (AR, MK), speed (NO, CS) and technical factor (GS, AI, SI, MC, EI) as well as Roberts et al. (2000, Table 2).
On the other hand, I am very hesitant to use the models employed by others in where there is no (or few) cross-loadings. This won’t be consistent with my series of EFAs from which I have got a lot of cross-loadings everywhere. As noted earlier, incorrectly specifying a non-zero cross-loading to be zero (or the reverse) will lead to misspecification, a situation we must avoid. I believe it is safer to just follow the pattern loadings produced by my own EFAs on the NLSY97.

Here I present my oblique factor analyses. From the left to the right : blacks, hispanics, whites. Some numbers were missing because I requested SPSS to not display coefficients lower than 0.10 (either positive or negative). This will ease the readability. I have chosen the ASVAB without AO subtests because after many runs, it seems the removal of AO yields the more coherent pattern of all. Furthermore, AO appears to be a spatial ability, which may not be unambiguously related to any of the factors revealed by EFAs.
Allowing cross-loadings or/and correlated errors does not really affect structural coefficient paths, but just the factor loadings in the ASVAB measurement model, at least in the present case. Also, when indicators load on multiple factors, their standardized loadings are interpreted as beta weights (β) that control for correlated factors (Kline, 2011, p. 231). Because beta weights are not correlations, one cannot generally square their values to derive proportions of explained variance.
3.2. SEM. Structural model.
When deciding to select standardized or unstandardized estimates, we should bear in mind that the numbers near the curved double-headed arrows represent covariances in unstandardized estimates, and correlations in standardized estimates. Remember that a covariance is the unstandardized form of a correlation; a correlation is computed by dividing covariance by the SD of both variables, removing thus the units of measurement (but rendering correlation sensitive to range restriction in SD). In the standardized solution, the numbers just above the variables having an error term represent the R² values summarizing the % of variance in the dependent variable explainable by the predictor(s). In unstandardized solution, we don’t have this number but instead the estimates of the error variance.

Above is a picture from AMOS graphics (for the black sample). From the measurement model ASVAB, we see the loadings of the indicators on the first-order factors and the loadings of the first-order factors on the second-order factor, namely, g. In order to obtain the factor loading of the indicators on the second-order factor (g) we must multiply the loading of the indicator on the first-order factor by the loading of this first-order factor on the second-order factor (Browne, 2006, p. 335). So for instance, in the case of General Science (GS) the loadings on g is 0.84*0.94=0.79, and for Coding Speed (CS) the loading on g is 0.67*0.81=0.54. The numbers associated with the indicators, such as 0.71 for GS or 0.44 for CS, represent the variance explained by the factor because 0.84^2=0.71. In the SEM framework, this value of 0.71 is also interpreted as the lower-bound reliability of this variable.
The direct paths from the independent var. to the dependent var. can be interpreted as the effect of this independent var. on the dependent var. when partialling out the influence of the other independent var. Although it is possible to reverse the direction of the arrows, instead of SES->g we will have g->SES, this would be methodologically unwise. Children’s IQ cannot cause (previously) reported parental SES. And the coefficients stay the same anyway. This is because both patterns impose the same restriction on the implied covariance matrix (Tomarken & Waller, 2003, p. 580). These models are conceptually different but mathematically equivalent. Similarly, if we remove the error term (e21) from ASVAB_g and draw a covariance between ASVAB_g and SES, the paths ASVAB->Achiev and SES->Achiev stay the same. Remember that these structural direct paths can be interpreted as B and Beta coefficients in multiple regression analyses (we only need to specify a covariance between the predictors).
For the analyses, I notice that the correlation of residuals between mom_educ and dad_educ systematically increases (modestly) the positive direct path SES->Achiev.
a) ASVAB.
Here I present the results from the original data (Go to the end of the post for the imputed data) using ML. With regard to the imputed data, for blacks, the effect of g on Achiev is somewhat smaller (~0.030) whereas the effect of parental SES on Achiev is higher (~0.030). In total, the overall difference is not trivial. Hopefully, for hispanics and whites, there was virtually no difference in the pooled imputed and the original data.
In the case of blacks, the direct path SES->Achiev amounts to 0.37. The paths SES->g and g->Achiev amount to 0.60 and 0.50, which yields a Beta coefficient of 0.60*0.50=0.30 for the indirect effect of SES on Achiev. The total effect is thus 0.37+0.30=0.67, compared to 0.50 for g. In the model with only SES and Achiev factors, the path is 0.64, thus the amount of mediation could be 0.64-0.37=0.27.
In the case of hispanics, the direct path SES->Achiev amounts to 0.24. The paths SES->g and g->Achiev amount to 0.63 and 0.52, which yields a Beta coefficient of 0.63*0.52=0.33 for the indirect effect of SES on Achiev. The total effect is thus 0.24+0.33=0.57, compared to 0.52 for g. In the model with only SES and Achiev factors, the path is 0.50, thus the amount of mediation could be 0.50-0.24=0.26.
In the case of whites, the direct path SES->Achiev amounts to 0.38. The paths SES->g and g->Achiev amount to 0.52 and 0.56, which yields a Beta coefficient of 0.52*0.56=0.29 for the indirect effect of SES on Achiev. The total effect is thus 0.29+0.38=0.67, compared to 0.56 for g. In the model with only SES and Achiev factors, the path is 0.67, thus the amount of mediation could be 0.67-0.38=0.29.
Next, I re-conduct the analysis this time using a latent GPA from 5 measures (english, foreign languages, math, social science, life and physical sciences) instead of Achiev factor (GPA+grade). Among blacks and whites, the direct effect of SES on GPA is very small (0.11 and 0.16), and has a negative sign among hispanics (-0.07).

b) ACT/SAT.
Here, I report the result from ML method. I have not used imputations because lack of time and because the % of missing values is extremely high. In ACT variables when SES and GPA/grade variables are included in an analysis of missing data patterns this amounts to 87% for blacks, 93% for hispanics, 80% for whites. The respective numbers for SAT variables (math and verbal) are 89%, 89%, 79%.
Also, remember that the residuals for ACT-English and ACT-Read are here correlated, as well as the residuals for mother and father’s education.
In the case of blacks, the direct path SES->Achiev amounts to 0.33. The paths SES->ACT-g and ACT-g->Achiev amount to 0.56 and 0.66, which yields a Beta coefficient of 0.56*0.66=0.37 for the indirect effect of SES on Achiev. The total effect for SES is thus 0.33+0.37=0.70, compared to 0.66 for ACT-g. In the model with only SES and Achiev factors, the path is 0.64, thus the amount of mediation could be 0.64-0.33=0.31.
In the case of hispanics, the direct path SES->Achiev amounts to 0.16. The paths SES->ACT-g and ACT-g->Achiev amount to 0.64 and 0.60, which yields a Beta coefficient of 0.64*0.60=0.38 for the indirect effect of SES on Achiev. The total effect for SES is thus 0.16+0.38=0.54, compared to 0.60 for ACT-g. In the model with only SES and Achiev factors, the path is 0.50, thus the amount of mediation could be 0.50-0.16=0.34.
In the case of whites, the direct path SES->Achiev amounts to 0.24. The paths SES->ACT-g and ACT-g->Achiev amount to 0.58 and 0.76, which yields a Beta coefficient of 0.58*0.76=0.44 for the indirect effect of SES on Achiev. The total effect for SES is thus 0.24+0.44=0.68, compared to 0.76 for ACT-g. In the model with only SES and Achiev factors, the path is 0.67, thus the amount of mediation could be 0.67-0.24=0.43.
For SAT-g (using the verbal and math sections as observed variables), the paths SES->Achiev, SES->SAT-g, SAT-g->Achiev amount to 0.43, 0.61, 0.39 for blacks, 0.40, 0.33, 0.48 for hispanics, and 0.30, 0.58, 0.67 for whites. Clearly, these numbers seem impressively disparate.
Here again, I re-conduct the analysis this time using a latent GPA from 5 measures (english, foreign languages, math, social science, life and physical sciences) instead of Achiev (GPA+grade). For ACT, among blacks and whites, the direct effect of SES on GPA amounts to zero, and has a negative sign among hispanics (-0.193). In the model with only SES and GPA, the SES->GPA path is 0.28 (blacks), 0.17 (hispanics), 0.41 (whites).
3.3. Replication of Brodnick & Ree (1995).
Brodnick & Ree (1995) attempted to show which structural model best summarizes the relationship between parental SES, SAT/ACT-g, and GPA (school grades). They demonstrate that the addition of a latent SES factor to SAT/ACT-g and GPA latent factors do not improve model fit over a model with only SAT/ACT-g and GPA latent factors. This finding has been interpreted as to say that after including g, SES has no additional explanatory power. This is probably because in Brodnick & Ree, their two other indicators (parental age, family size) are irrelevant as measuring parental SES. Their table 2 shows that these variables do not correlate with any other ones, except family size with income but modestly (0.181). Hence the absence in model fit increment. When I try to replicate their model (using the original data set, not the imputed, with ML method), as shown in their figures, the finding was different. A model including latent SES has better fit than a model with no latent SES. I have used the same variable as the above cited; but concerning GPA, I have included 5 measures (english, foreign language, math, social sciences, life sciences) for constructing the latent GPA factor. Now, the reason why I have failed to confirm their result is obvious. All of my observed variables truly measure SES in a good way. So, the model including the latent SES shows improvement in fit.
4. Limitations.
The first obvious limitation is that ASVAB seems truly be awful. Roberts et al. (2000) rightly point out that “The main reason the ASVAB was constructed without any obviously coherent factorial structure is quite clear. The initial purpose of this multiple-aptitude battery was as a classification instrument. Therefore, tests were selected on the basis of perceived similarities to military occupations rather than any psychological theory.” (pp. 86-87). The authors advanced the idea that because the ASVAB is scholastic/verbally biased, it measures purely scholastic competence. But the fact that ASVAB g-factor score as well as its subtest g-loadings correlate with reaction time test, a prototypical measure of fluid intelligence excludes this interpretation (Jensen, 1998, pp. 236-238; Larson et al., 1988). In any case, the fact remains that ASVAB still needs to be revised. And not only because it is racially biased (e.g., when performing MGCFA).
We note a problem with GPA as well. The loading of GPA on the achievement factor is around 0.54 and 0.58 for blacks and hispanics but amounts to 0.76 for whites. When I use a latent GPA in my outcome variable, the R² for blacks and hispanics amounts to 0.19 and 0.16, but amounts to 0.43 for whites. A great amount of % is left unexplained by the same set of variables for minority groups, suggesting additional factors not accounted for by the set of predictors (but statistical artifacts could be suspected too, e.g., higher difficulty causing piling up of scores at the low end distribution and thus a reduction in variance of scores). For ACT-g, the respective numbers for blacks, hispanics and whites are 0.46, 0.42, and 0.72. For SAT-g, the numbers are 0.31, 0.39, 0.63. Why the huge difference in predictive validities ? Because the GPA score is a transcript record from school, that means minorities can’t be suspected to inflate their score or something (see NLSY97 Appendix-11). Perhaps GPA has different meanings for blacks/hispanics compared to whites. The same grade may lack comparison at the between-school level, because schools differ in quality. Therefore, I would have expected similar conclusions for Grade variable (highest lvl of education completed) but there was no such minority-majority difference, the R² is similar (somewhat) for blacks and whites but clearly lower (by 0.10-0.15) for hispanics. Now, it must be mentioned that R² is not always easy to interpret and that a convertion of R² in odds ratio reveals that even a low R² can be truly meaningful (Sackett et al., 2008, p. 216; Jensen, 1980, pp. 306-307).
Another dissatisfaction concerns the impact of imputations on the parameter estimates. Compared to ML results, the distortion is not trivial for blacks, with ASVAB(g)->Achiev constantly at about 0.46 or 0.47 (0.50 for ML) and SES->Achiev constantly at about 0.40 (0.37 for ML), whereas that difference approaches zero for whites and hispanics. Hence, I performed again the imputation (10 datasets) for each groups, with Linear Regression method and then PMM method. In total, 60 imputation data. At first glance, both method yield the same results. This time, the parameter values look closer to those obtained with maximum likelihood. Interestingly, the paths SES->ASVAB and ASVAB->Achiev appear more or less stable. This wasn’t the case for SES->Achiev. The reason is obvious : the ASVAB variables have no missing values. Furthermore, it seems that SES->Achiev has more stability among whites than among blacks or hispanics. I would guess it was because the white sample had much less missing values. My first impression with regard to imputation is not good. With about 10, 20 and 30% missing for some variables, choosing 5 imputed datasets may not be wise. I believe we need much more than this. Perhaps 15 or 20 at minimum.
Concerning the mediational effect of parental SES on GPA, the removing of SES->GPA path does not impact the model fit, unlike ASVAB/ACT/SAT->GPA path. This looks curious because in the black and white sample for the ASVAB model, the path is 0.11 and 0.16, clearly different from zero, but the impact on model fit is not all clear. Either that means SES (independent of g) has really no meaningful impact on GPA, or that fit indices are not sensitive enough in the detection of misspecification. I would say the first hypothesis seems more likely.
When examining the total effect of SES versus total effect of ASVAB, or ACT/SAT, it would seem that parental SES is more important than ASVAB in predicting the achievement. But knowing that the pre-requisite for causal inferences has probably not been met here (e.g., controlling for previous SES and IQ when examining the impact of the mediators by having SES, IQ, grade variables also at previous waves) I would not recommend to misinterpret these numbers. The only robust conclusion presently is that the direct path SES->achiev is much less than the direct path ASVAB/ACT/SAT->achiev, consistent with Jensen’s earlier statement.
Both univariate and multivariate non-normality have the potential to distort parameter estimates and to falsely reject models. They seriously should be taken into account. Concerning the outliers, I have detected only two cases (in the black sample). These were the highest d² values, 67 and 62, that depart somewhat from the values that follow immediately after them, i.e., 52, 51, 51, 50, 47, 46, 46, and so forth. Those two values removed, I see no change in the parameter estimates and fit indices. It’s likely that their impact have been attenuated by the large N. Next is the univariate skew and kurtosis. None of the variables exceeded 2 for skew or 10 for kurtosis. The highest values were for Dad_educ and Mom_educ with kurtosis of about ~2.5 and ~1.5, respectively, in the black sample again. The values of multivariate kurtosis ranged between 18 and 19, between 13 and 14, between 21 and 22, in black, hispanic, and white samples, respectively. As can be seen, there is no great variability in the kurtosis values due to imputation. Anyway, these values were much lower than Bollen’s (1989) threshold value of p(p+2) which equals to 16*(16+2)=288, for p being the number of observed variables. With respect to the bootstrap estimates, they reveal no difference compared with ML estimates for each of the imputed data sets.
5. Discussion.
Truly, that post is just a pretense for showing how SEM works. So, don’t get me wrong. There is nothing special in this analysis or even in his conclusion. It’s just boring and doesn’t worth the huge amount of time I spent on it. Nevertheless, some comments are worth mentioning.
The fact that parental SES correlates with child’s (later) success does not imply the link works entirely through an environmental path (Trzaskowski et al., 2014). Earlier studies show that children’s IQ has a stronger relationship with children’s later SES (at adulthood) than parental SES with children’s later SES (Herrnstein & Murray, 1994, ch. 5 and 6; Jensen, 1998, p. 384; Saunders, 1996, 2002; Strenze, 2007, see Table 1 (column p) and footnote 9). This pattern is more consistent with a causal path from earlier IQ toward later SES than the reverse. To some extent, this is also in line with a path analysis study showing that earlier IQ causing later IQ+achievement is a more likely hypothesis than earlier achievement causing later IQ+achievement (Watkins et al., 2007).
And, as we see above, ACT-g has a much more explanatory power than ASVAB-g on the Achievement factor. One possible reason is that ACT has more scholastic component in it; another is that ACT measures g much better than ASVAB although I see no specific reason for this. Anyway, the difference seems huge enough. This could be consistent with Coyle & Pillow (2008, Figure 2) who concluded that ACT and SAT still predict GPA even after removing the influence of ASVAB-g, with Beta coefficients similar to that of g.
Recommended readings for introduction on SEM :
Beaujean Alexander A. (2012). Latent Variable Models in Education.![]()
Hooper Daire, Coughlan Joseph, Mullen Michael R. (2008). Structural Equation Modelling: Guidelines for Determining Model Fit.![]()
Hu Changya (2010). Bootstrapping in Amos.![]()
Kenny David A. (2011). Terminology and Basics of SEM.![]()
Kenny David A. (2013). Measuring Model Fit.![]()
Lei Pui-Wa and Wu Qiong (2007). Introduction to Structural Equation Modeling: Issues and Practical Considerations.![]()
Tomarken Andrew J., Waller Niels G. (2005). Structural Equation Modeling: Strengths, Limitations, and Misconceptions.![]()
Recommended readings on technical issues related to SEM :
Allison Paul D. (2002). Missing data.![]()
Allison Paul D. (2009). Missing Data, Chapter 4, in The SAGE Handbook of Quantitative Methods in Psychology (Millsap, & Maydeu-Olivares, 2009).![]()
Allison Paul D. (November 9, 2012). Why You Probably Need More Imputations Than You Think.![]()
Andridge Rebecca R., Little Roderick J. A. (2010). A Review of Hot Deck Imputation for Survey Non-response.![]()
Baron Reuben M., Kenny David A. (1986). The Moderator-Mediator Variable Distinction in Social Psychological Research: Conceptual, Strategic, and Statistical Considerations.![]()
Bentler P.M., Chou Chih-Ping (1987). Practical Issues in Structural Modeling.![]()
Browne Michael W., MacCallum Robert C., Kim Cheong-Tag, Andersen Barbara L., Glaser Ronald (2002). When Fit Indices and Residuals Are Incompatible.![]()
Cheung Gordon W., Rensvold Roger B. (2001). The Effects of Model Parsimony and Sampling Error on the Fit of Structural Equation Models.
Cheung Gordon W., Lau Rebecca S. (2008). Testing Mediation and Suppression Effects of Latent Variables: Bootstrapping With Structural Equation Models.
Cole David A., Maxwell Scott E. (2003). Testing Mediational Models With Longitudinal Data: Questions and Tips in the Use of Structural Equation Modeling.![]()
Cole David A., Ciesla Jeffrey A., Steiger James H. (2007). The Insidious Effects of Failing to Include Design-Driven Correlated Residuals in Latent-Variable Covariance Structure Analysis.
Costello Anna B. & Osborne Jason W. (2005). Best Practices in Exploratory Factor Analysis: Four Recommendations for Getting the Most From Your Analysis.![]()
Fan Xitao, Sivo Stephen A. (2007). Sensitivity of Fit Indices to Model Misspecification and Model Types.![]()
Gao Shengyi, Mokhtarian Patricia L., Johnston Robert A. (2008). Nonnormality of Data in Structural Equation Models.![]()
Graham John W. (2009). Missing Data Analysis: Making It Work in the Real World.![]()
Grewal Rajdeep, Cote Joseph A., Baumgartner Hans (2004). Multicollinearity and Measurement Error in Structural Equation Models: Implications for Theory Testing.![]()
Hardt Jochen, Herke Max, Leonhart Rainer (2012). Auxiliary variables in multiple imputation in regression with missing X: A warning against including too many in small sample research.![]()
Heene Moritz, Hilbert Sven, Draxler Clemens, Ziegler Matthias, Bühner Markus (2011). Masking Misfit in Confirmatory Factor Analysis by Increasing Unique Variances: A Cautionary Note on the Usefulness of Cutoff Values of Fit Indices.![]()
Hopwood Christopher J. (2007). Moderation and Mediation in Structural Equation Modeling: Applications for Early Intervention Research.
Kenny David A. (2011). Miscellaneous Variables.![]()
Kenny David A. (2011). Single Latent Variable Model.![]()
Kline Rex B. (2013). Reverse arrow dynamics: Feedback loops and formative measurement.![]()
Koller-Meinfelder Florian (2009). Analysis of Incomplete Survey Data – Multiple Imputation via Bayesian Bootstrap Predictive Mean Matching.![]()
Lee Katherine J., Carlin John B. (2009). Multiple Imputation for Missing Data: Fully Conditional Specification Versus Multivariate Normal Imputation.![]()
Little Todd D., Cunningham William A., Shahar Golan (2002). To Parcel or Not to Parcel: Exploring the Question, Weighing the Merits.![]()
MacCallum Robert C., Roznowski Mary, Necowitz Lawrence B. (1992). Model Modifications in Covariance Structure Analysis: The Problem of Capitalization on Chance.![]()
MacKenzie Scott B., Podsakoff Philip M., Jarvis Cheryl Burke (2005). The Problem of Measurement Model Misspecification in Behavioral and Organizational Research and Some Recommended Solutions.![]()
Osborne, Jason W. & Amy Overbay (2004). The power of outliers (and why researchers should always check for them).![]()
Reddy Srinivas K. (1992). Effects of Ignoring Correlated Measurement Error in Structural Equation Models.
Savalei Victoria (2012). The Relationship Between Root Mean Square Error of Approximation and Model Misspecification in Confirmatory Factor Analysis Models.
Sharma Subhash, Mukherjeeb Soumen, Kumarc Ajith, Dillon William R. (2005). A simulation study to investigate the use of cutoff values for assessing model fit in covariance structure models.
Tomarken Andrew J., Waller Niels G. (2003). Potential Problems With “Well Fitting” Models.
van Buuren Steph (2007). Multiple imputation of discrete and continuous data by fully conditional specification.![]()
van Buuren Steph, Brand J.P.L., Groothuis-Oudshoorn C.G.M., Rubin D.B. (2006). Fully conditional specification in multivariate imputation.![]()
Required readings for AMOS users :
Structural Equation Modeling using AMOS: An Introduction.![]()
Structural Equation Models: Introduction – SEM with Observed Variables Exercises – AMOS.![]()
Confirmatory Factor Analysis using Amos, LISREL, Mplus, SAS/STAT CALIS.![]()
Required books for AMOS users :
Arbuckle James L. (2011). IBM® SPSS® Amos™ 20 User’s Guide.![]()
Byrne Barbara M. (2010). Structural Equation Modeling With AMOS: Basic Concepts, Applications, and Programming, Second Edition.![]()
Kline Rex B. (2011). Principles and Practice of Structural Equation Modeling, Third Edition.![]()
Required books for SPSS users :
IBM SPSS Missing Values 20.![]()
Graham John W. (2012). Multiple Imputation and Analysis with SPSS 17-20.
*The XLS spreadsheet is here. The syntax is displayed here.*

Que pensez vous de cette vidéo ?
Pourrait-elle être une piste pour expliquer la faiblesse de QI de certaines catégories de personnes : http://www.youtube.com/watch?v=K6OYrkyYiDY ?
Je viens de voir. C’est vraiment instructif. J’avais déjà lu des études sur le fait que les enfants qui consommaient plus de sucres devenaient plus violents (et avaient de moins bonnes notes scolaires au passage) à l’âge adulte. J’imaginais que c’était les individus qui avaient déjà au préalable certaines caractéristiques qui les prédisposaient au crime, et que ce n’était pas nécessairement lié à la nutrition. Mais les études présentées ici sont des expériences où apparemment on manipule l’alimentation d’un groupe d’individu tiré aléatoirement, pour le comparer à un groupe de contrôle. L’effet causal est plus évident sur ce genre d’étude, et je pense que la preuve est assez éclatante.
Mais le fait est que le sucre (ou les additifs comme le glutamate qui stimulent l’hyperactivité) se retrouve partout dans nos aliments, du fait que les industriels connaissent notre goût pour le sucre. Ou une façon de dire que le business provoque le crime ?
Aussi, fait intéressant, je me rappelle que les africains aux USA (et probablement en Europe bien que je manque de chiffres) consomment beaucoup plus de sucres que n’importe quel autre groupe. Or, nous savons tous que le taux de crimes est également beaucoup plus élevé.
Concernant les effets de l’alimentation sur le QI, je doute que le sucre ait des impacts directs, mais peut-être indirects, du genre, la propension à la violence cause plus de risques d’accidents graves au niveau du cerveau. Mais ce genre de cas est probablement rare. Enfin, à ma connaissance, les effets de l’alimentation sont majeures pour les enfants qui ne mangent pas assez (sous-nutrition) d’environ peut-être 5-10 points. Mais comprenez que dans les pays développés, il n’y a pas ou presque d’enfants frappés de sous-nutrition.
Je viens de trouver un très bon site francophone sur le Q.I
http://www.intelligence-humaine.com
Il y a également un blog en lien avec le site blog.intelligence-humaine.com
Vous devriez essayer de travailler ensemble sur un seul et meme blog pour augmenter la visibilité de toutes ces informations fondamentales pour notre avenir.
Ce site, c’est nul. Je le connais. Il n’a jamais été capable d’argumenter de façon critique les articles qu’il cite. Son maximum, c’est rapporter les tableaux et graphs. Mais aucune interprétation des régressions et autres modèles multivariées. Il est probablement très limité en statistique, ce qui n’est pas mon cas. Je peux commenter pratiquement n’importe quel article de façon structurée. Si vous parlez à ce type de MGCFA, ou SEM, son cerveau va surchauffer. Moi, je peux maitriser ces techniques, et comprends leur base théorique. Tout n’est pas à jeter sur son site, néanmoins. Ses connaissances sont largement supérieures à la moyenne, malheureusement pour lui, mon niveau est infiniment supérieur au sien. Sur les sites français, je doute que vous trouverez mieux que mon blog. Vous pouvez lire ces deux articles pour en avoir une idée.